Variable Selection: Choosing What Your Model Gets to See
LASSO, ridge, stepwise methods, and the bias-variance tradeoff
The Problem: Too Many Variables
Every model we’ve built so far uses factors (predictor variables) to make predictions. But how many factors should a model actually use? There are two compelling reasons to prefer fewer:
1. Overfitting risk. When the number of factors approaches the number of data points, the model starts fitting random patterns in addition to real ones. With only 3 data points and 1 factor, different samples produce wildly different regression lines. With enough factors relative to data, even meaningless ones (like the temperature 37 days after someone’s birth) appear to have predictive power.
2. Simplicity and explainability. Fewer factors means:
- Less data collection cost
- Easier explanation to non-technical stakeholders
- Less chance of including a non-significant factor (20 factors at \(p = 0.05\) gives a 64% chance at least one is meaningless)
- Legal compliance: In credit decisions, factors like race, sex, religion, and marital status are forbidden. Overly complex models can use these indirectly through correlated proxies (zip code \(\rightarrow\) race, “lives in Utah” \(\rightarrow\) religion)
Key insight: If you can’t clearly communicate what your model is doing, it won’t be trusted or used — and in some industries, it would be illegal to use.
Greedy Methods: Step by Step
These methods make locally optimal decisions at each step without considering future consequences.
Forward Selection
Start with no factors. At each step, add the single best factor (lowest p-value or highest \(R^2\) improvement) if it’s “good enough” (e.g., \(p < 0.10\) to \(0.15\)). Stop when no remaining factor meets the threshold. Optionally remove weak factors at the end.
Backward Elimination
Start with all factors. At each step, remove the worst factor until nothing is “bad enough” to remove (e.g., all remaining factors have \(p < 0.05\)).
Stepwise Regression
Combines both: after adding each new factor, immediately check if any existing factors should now be removed. This allows the model to adjust as new factors change the picture. Most commonly used of the three.
All three can use p-values, \(R^2\), AIC, or BIC as the selection criterion.
Limitation: Greedy methods tend to overfit random effects and often don’t perform as well on new data compared to global methods.
LASSO: Budget Allocation
LASSO (Least Absolute Shrinkage and Selection Operator) takes a fundamentally different approach. Instead of stepping through factors one at a time, it adds a constraint to the regression optimization:
\[\sum_{j=1}^{p} |a_j| \leq T\]
The sum of the absolute values of all coefficients must be within a “budget” \(T\). The model allocates this budget to the most important coefficients, driving the rest exactly to zero — effectively removing those variables.
Critical requirement: LASSO requires scaled data because the constraint operates on coefficient magnitudes, and unscaled data means units affect which coefficients appear larger.
The right value of \(T\) is found by trying different values and comparing model quality (using cross-validation from the validation walkthrough).
Ridge Regression: Shrink, Don’t Remove
Ridge regression uses a similar constraint, but on squared coefficient values:
\[\sum_{j=1}^{p} a_j^2 \leq T\]
This shrinks all coefficients toward zero without eliminating any. It’s a form of regularization — reducing overfitting by constraining coefficient magnitudes rather than removing variables.
When to use ridge: When your linear regression model appears overfit (validation error much worse than training error) but you don’t want to remove variables entirely.
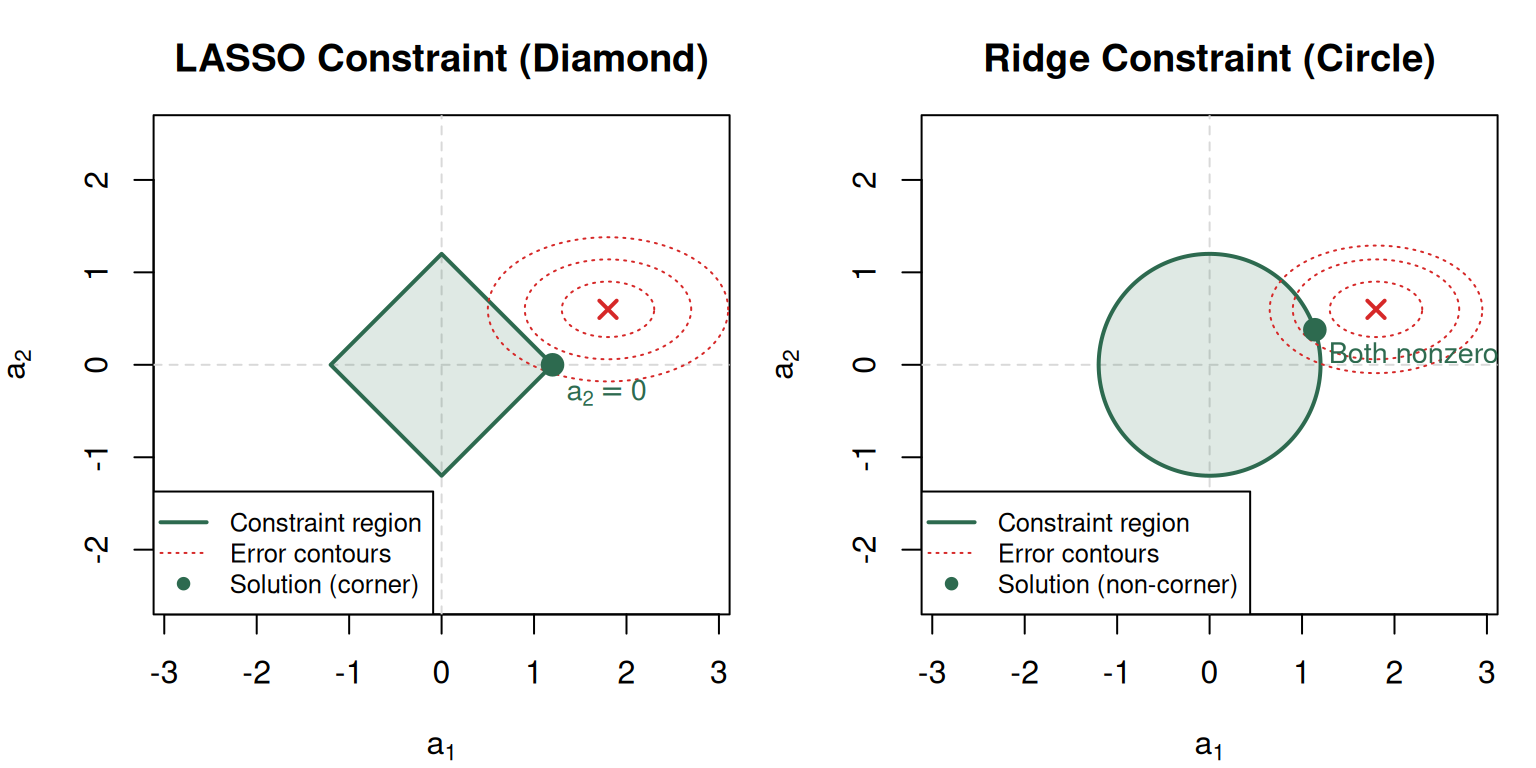
The Geometric Intuition: Why LASSO Removes Variables and Ridge Doesn’t
This is the core visual insight of the module. In 2D (two coefficients):
The key insight: The diamond has straight edges that create corners on the axes (where coefficients = 0). The expanding error ellipses almost always hit a corner first. The circle has a curved boundary — curved ellipses touching a curved surface almost never land on an axis. That’s the entire geometric explanation.
Bias-Variance Tradeoff
Every dataset contains real patterns (true effects) and random patterns (noise artifacts). Models can’t tell them apart — they can only fit more or less to all patterns simultaneously.
| Fits random patterns (high) | Avoids random patterns (low) | |
|---|---|---|
| Captures real patterns (high) | Overfitting danger | Sweet spot |
| Misses real patterns (low) | Worst case | Underfitting |
- Bias = error from missing real patterns (underfitting). Removing variables and shrinking coefficients increases bias.
- Variance = error from fitting random patterns (overfitting). More variables and larger coefficients increase variance.
The sweet spot minimizes total prediction error (bias + variance). Validation helps you find it, and domain experts can guide which patterns are likely real.
Practitioner note: He dislikes the terms “bias” and “variance” in this context — finds them confusing. The intuition (real vs. random patterns) matters more than the jargon.
Choosing a Method
| Method | Speed | Variable Selection? | Regularization? | Best For |
|---|---|---|---|---|
| Forward/Backward/Stepwise | Fast | Yes | No | Initial exploration |
| LASSO | Slower | Yes (zeros out coefficients) | Yes | Final predictive models |
| Ridge | Slower | No (shrinks only) | Yes | Reducing overfitting without removing variables |
| Elastic Net | Slower | Yes + shrinkage | Yes | Correlated predictors |
Elastic net combines LASSO (absolute value constraint) with ridge (quadratic constraint). With correlated factors, LASSO arbitrarily picks one; ridge includes both but may underestimate. Elastic net offers a middle ground.
Practical emphasis: “There’s a lot of art to analytics” — if you have time to try one method, you have time to try several and compare.
Common Pitfalls
WarningCommon Misconceptions
- Ridge regression does NOT do variable selection — it shrinks coefficients but never drives them exactly to zero.
- LASSO requires scaled data — because the absolute-value constraint is sensitive to coefficient magnitudes.
- Greedy methods can miss the best model — they make locally optimal choices that may not be globally optimal.
- Elastic net is not “LASSO but better” — it’s a tradeoff. With uncorrelated factors, LASSO alone may be cleaner.
- A tighter budget \(T\) in LASSO = more variables removed — not fewer. Smaller \(T\) forces more coefficients to zero.
- Bias-variance is about prediction on NEW data — training error alone doesn’t reveal the tradeoff.