Time Series From Scratch: Predicting What Comes Next
Exponential smoothing, ARIMA, and GARCH — three tools, one goal
1. The Problem: What Will Tomorrow’s Value Be?
You have data ordered in time — daily sales, monthly temperatures, hourly stock prices. The past has a pattern. Can you extend that pattern into the future?
This is forecasting: using the history of a value to predict where it’s going next.
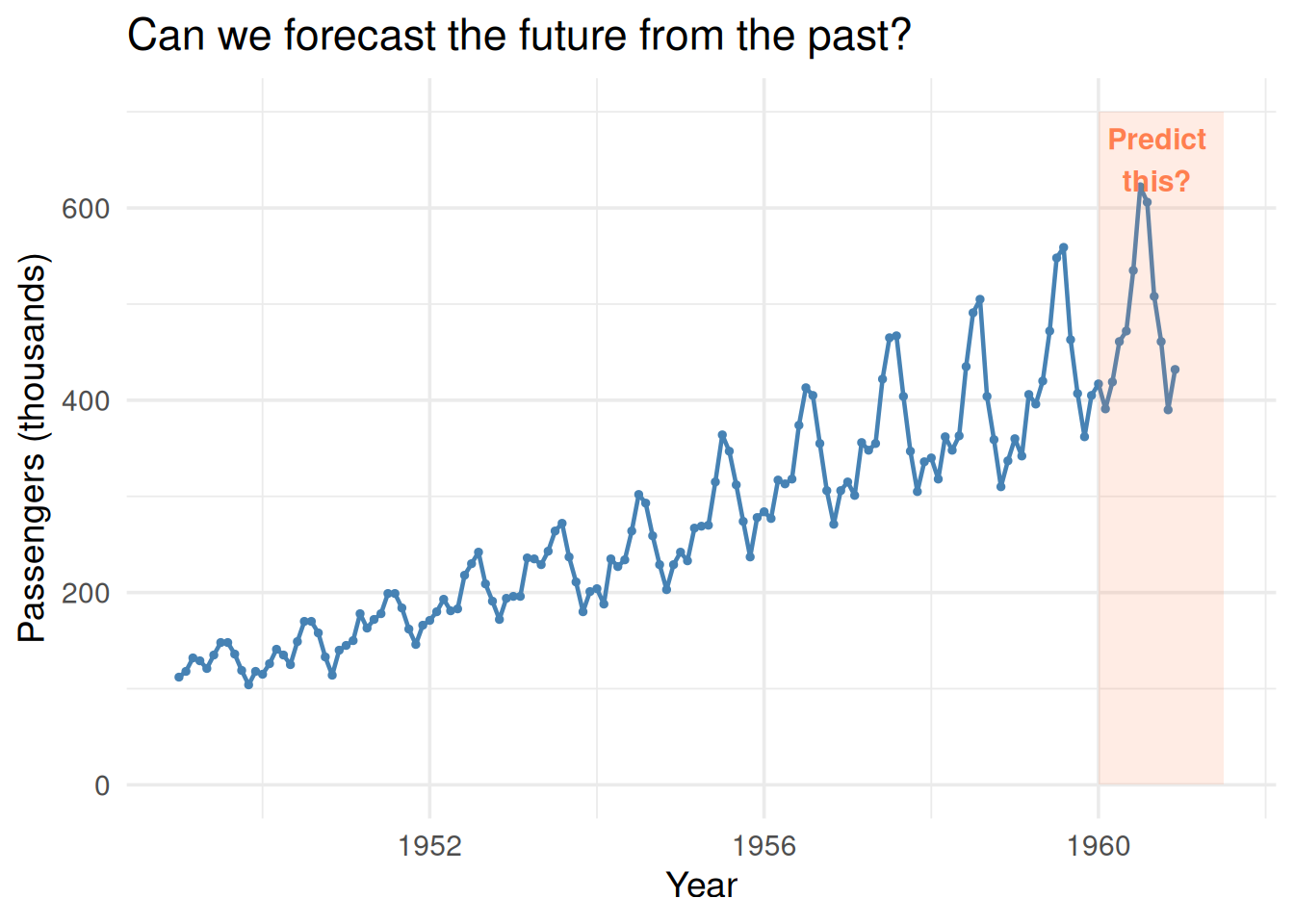
library(ggplot2)# Classic airline passengers datasetap <- AirPassengersdf_ap <-data.frame(time =as.numeric(time(ap)),passengers =as.numeric(ap))ggplot(df_ap, aes(time, passengers)) +geom_line(linewidth =0.8, color ="steelblue") +geom_point(size =0.8, color ="steelblue") +annotate("rect", xmin =1960, xmax =1961.5, ymin =0, ymax =700,fill ="coral", alpha =0.15) +annotate("text", x =1960.7, y =650, label ="Predict\nthis?",color ="coral", fontface ="bold", size =4) +theme_minimal(base_size =14) +labs(x ="Year", y ="Passengers (thousands)",title ="Can we forecast the future from the past?")
Figure 1: Monthly airline passengers — a clear trend and seasonal pattern. What comes next?
Three patterns appear in time series data:
Pattern
What it looks like
Example
Level
Flat, bouncing around a constant
Daily temperature in a stable climate
Trend
Going steadily up or down
Company revenue growing year over year
Seasonality
Repeating cycle at fixed intervals
Retail sales spiking every December
Different forecasting methods handle different combinations of these.
2. Exponential Smoothing: The Weighted Average Approach
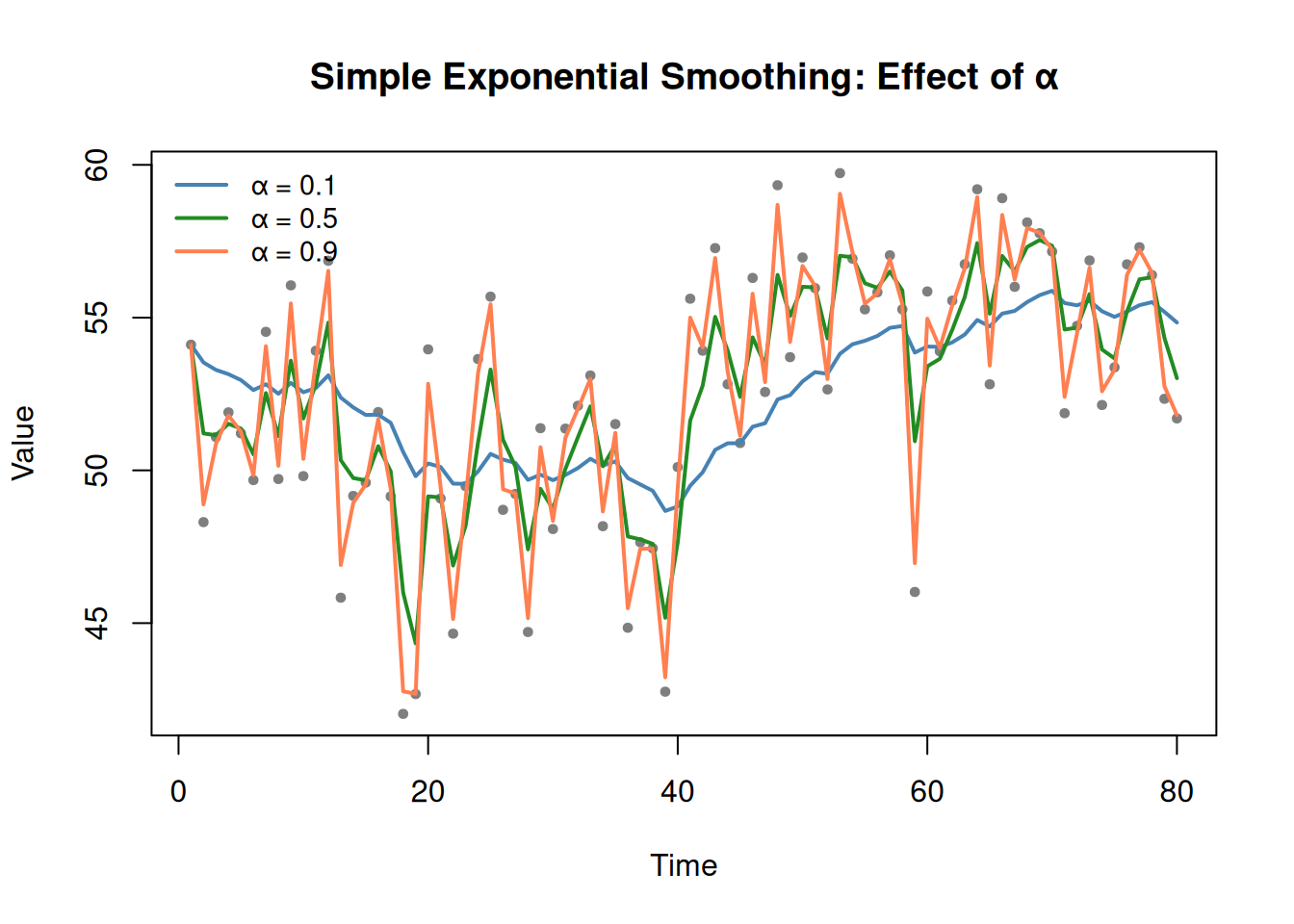
Simple Exponential Smoothing (Level Only)
The simplest idea: your forecast is a weighted average of the current observation and your previous forecast.
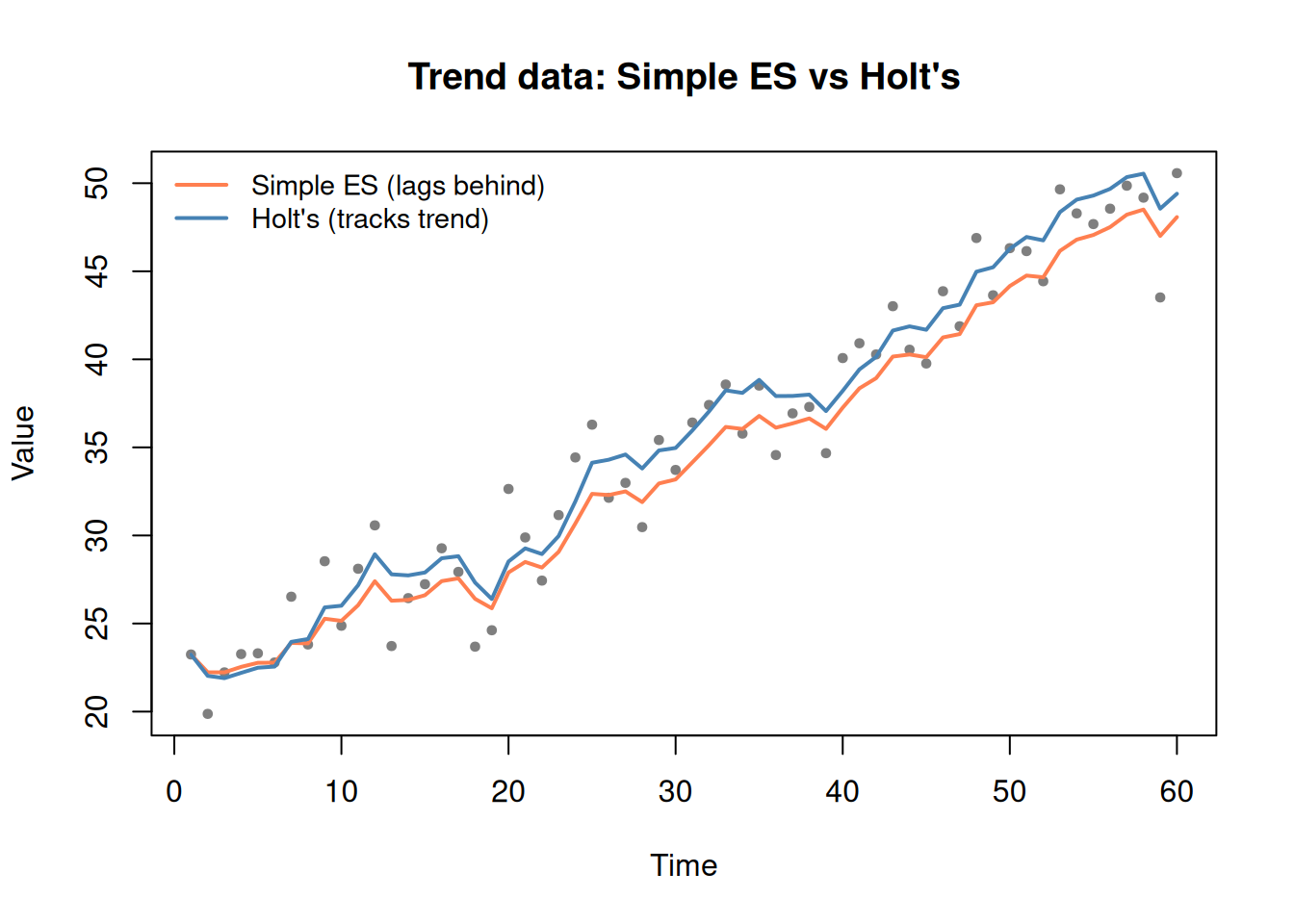
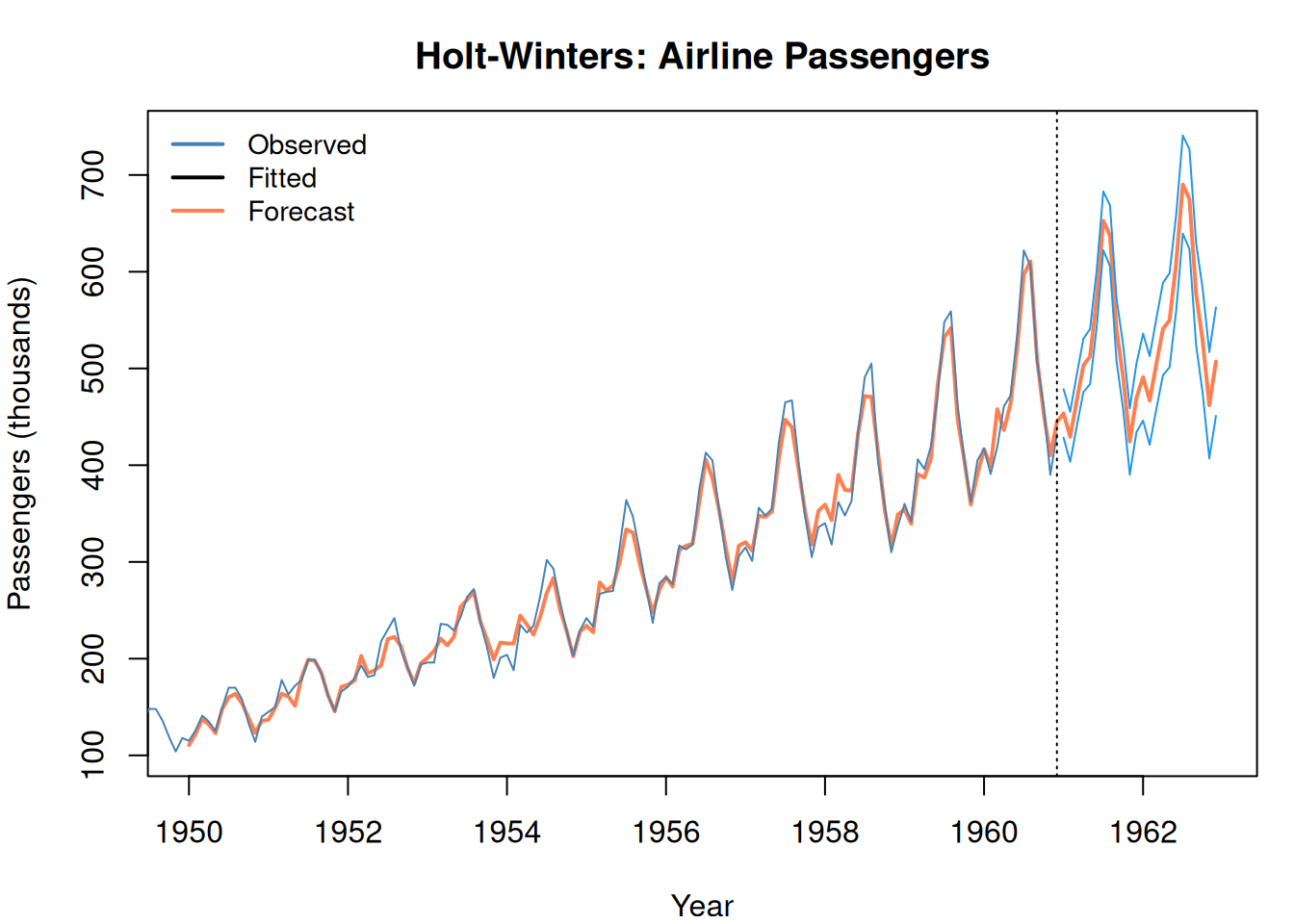
Figure 5: Holt-Winters captures trend AND seasonality
Which Exponential Smoothing to Use?
Does the data have a trend?
|
+-- No ──── Does it have seasonality?
| |
| +-- No ──── Simple ES (one parameter: α)
| +-- Yes ─── Seasonal ES
|
+-- Yes ─── Does it have seasonality?
|
+-- No ──── Holt (two parameters: α, β)
+-- Yes ─── Holt-Winters (three parameters: α, β, γ)
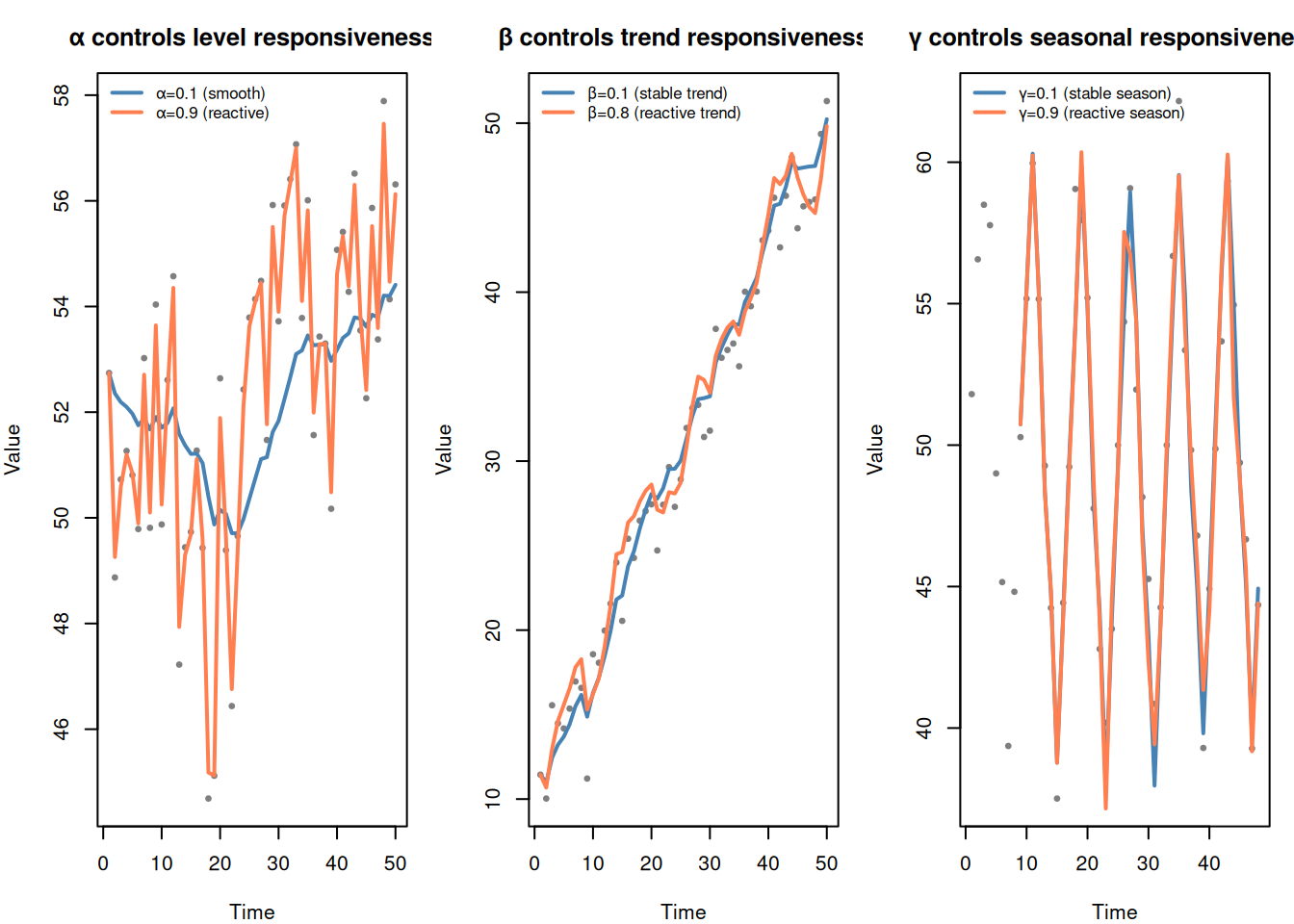
How to choose α, β, γ? Cross-validation (Module 3) — try different values, pick the ones that minimize forecast error on held-out data. R’s HoltWinters() does this automatically.
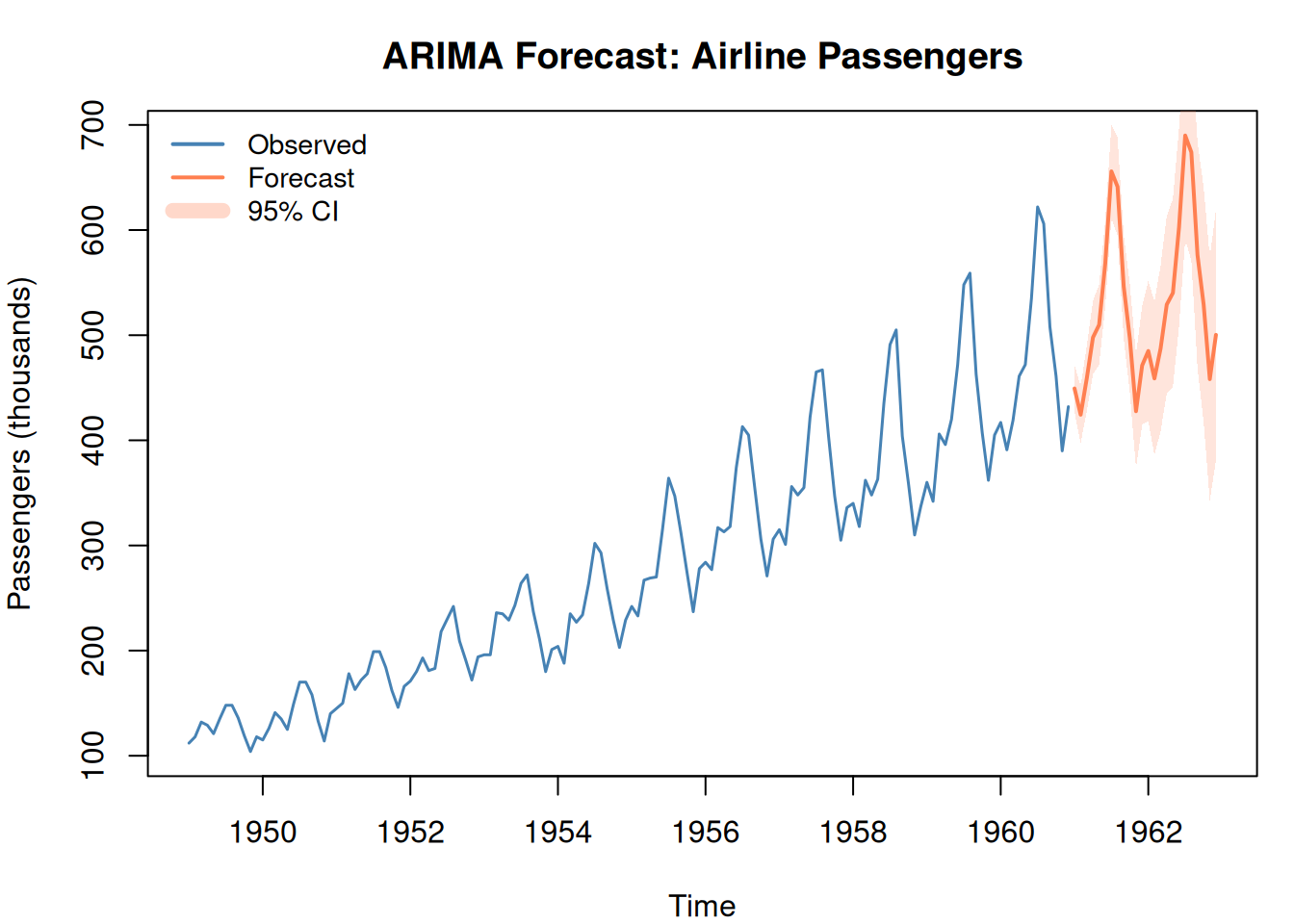
6. ARIMA: A Different Approach
Exponential smoothing is intuitive but limited in the patterns it can express. ARIMA is more flexible — it combines three ideas into one framework.
ARIMA(p, d, q) — What the Letters Mean
Letter
Name
What it does
p
AutoRegressive order
Use the last \(p\) values to predict the next
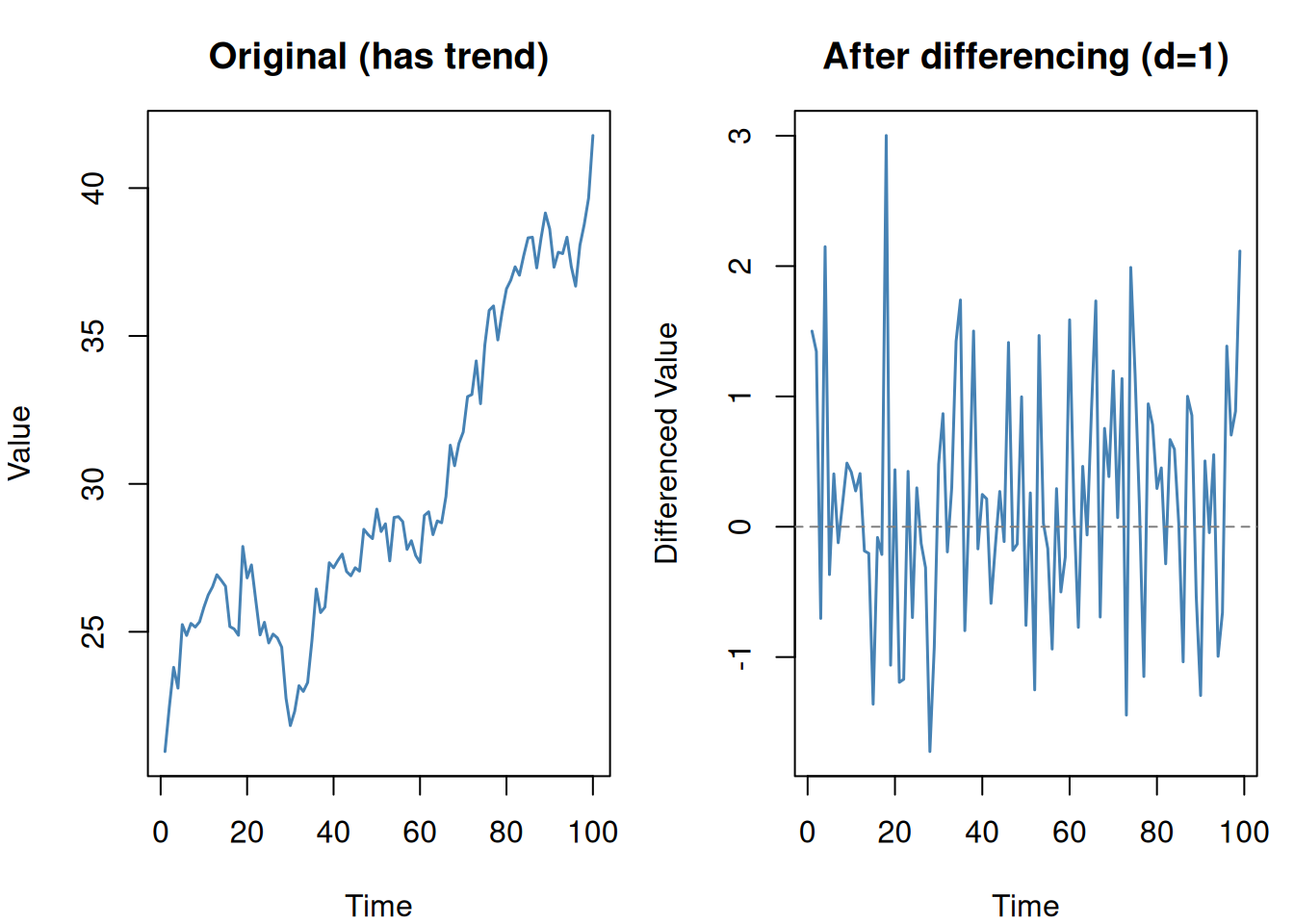
d
Differencing order
How many times to difference the data to remove trend
q
Moving Average order
Use the last \(q\) forecast errors to correct predictions
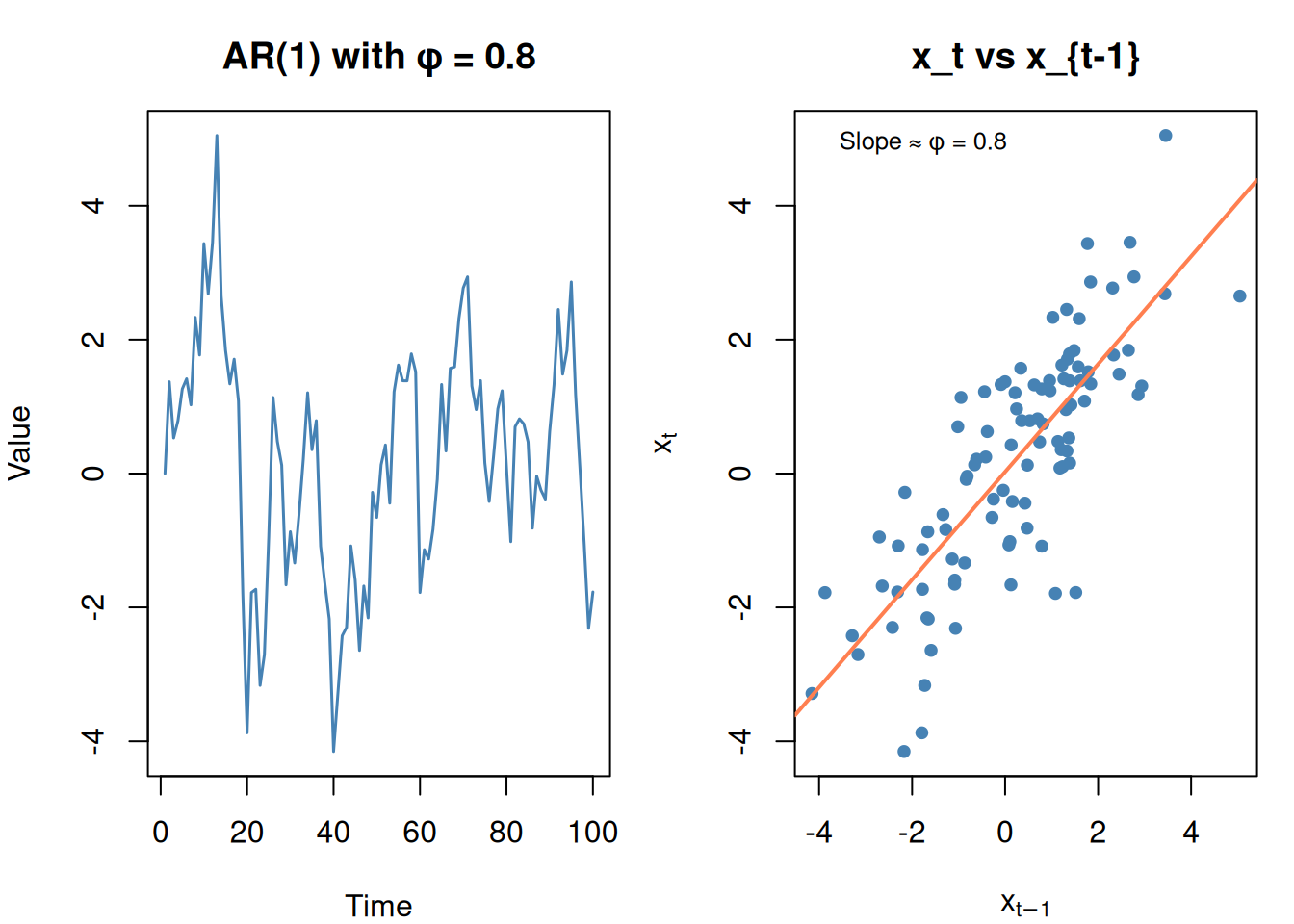
AR: Autoregressive (the “p” part)
Tomorrow’s value depends on today’s value (and maybe yesterday’s):
How much a single surprise increases future volatility
\(\beta_1\)
Persistence
How long volatility stays elevated after a shock
\(\sigma_{t-1}^2\)
Previous variance
Yesterday’s volatility forecast
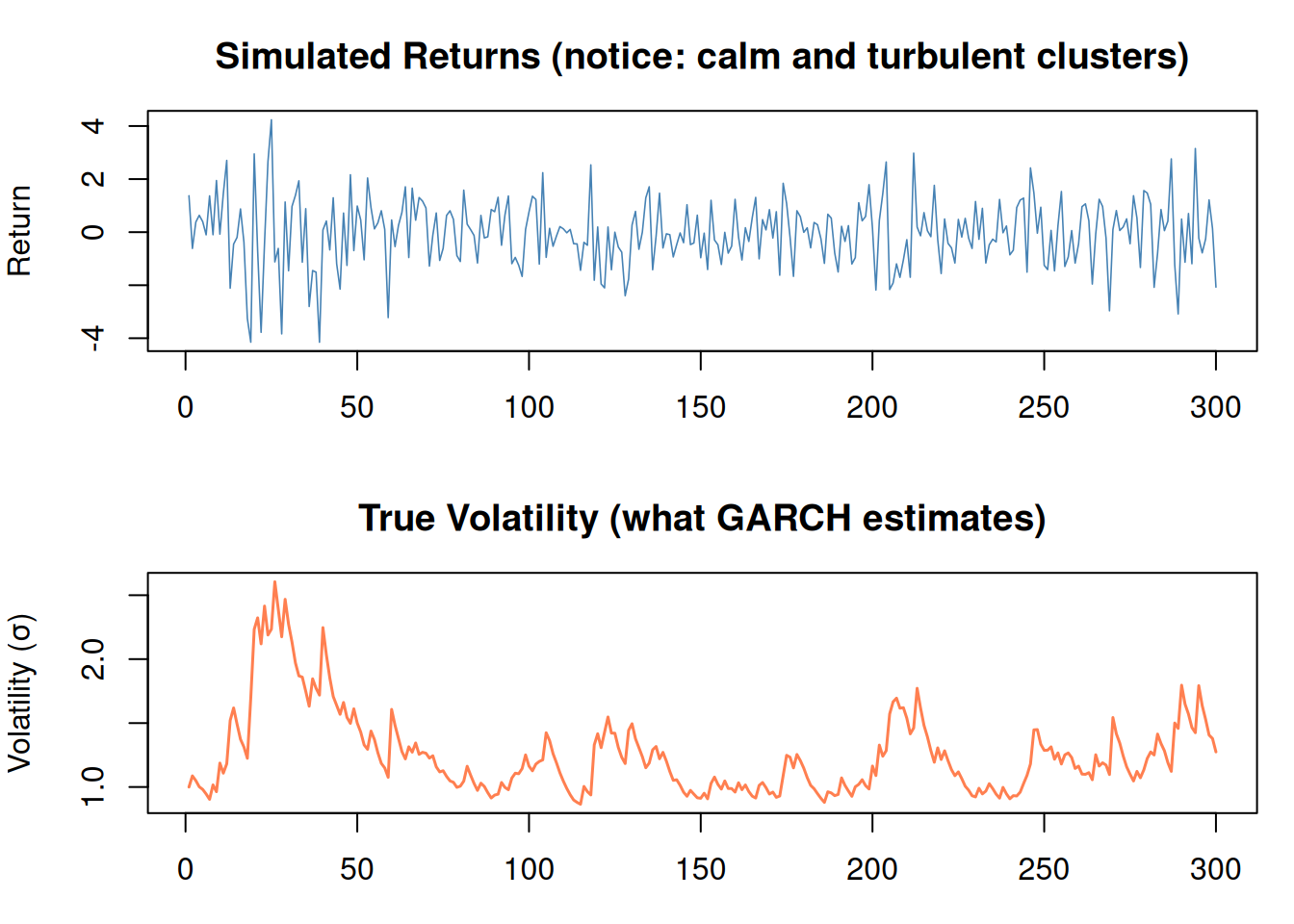
Key insight:\(\alpha\) captures shocks (a big surprise today → more volatility tomorrow). \(\beta\) captures persistence (volatility tends to stay high once it’s high).
Figure 10: Volatility clusters: calm periods and turbulent periods alternate
When to Use GARCH
A common practice check asks whether you know the difference:
Question asks about…
Use
“Forecast the value”
Exponential smoothing or ARIMA
“Forecast volatility/risk/variance”
GARCH
“Predict how much values will fluctuate”
GARCH
“Build confidence intervals that change over time”
GARCH
“Portfolio risk” or “Value at Risk”
GARCH
9. The Complete Decision Tree
What are you forecasting?
|
+-- The VALUE itself ──── Is there a trend? Seasonality?
| |
| +-- Level only ────────── Simple ES
| +-- Level + trend ─────── Double ES (Holt)
| +-- Level + trend + season ── Triple ES (Holt-Winters)
| +-- Complex pattern, lots of data ── ARIMA
|
+-- The VOLATILITY/VARIANCE ── GARCH
|
+-- Has something CHANGED? ── CUSUM (Module 6)
10. Cheat Sheet: The Whole Story on One Page
TIME SERIES FORECASTING RECIPE
================================
EXPONENTIAL SMOOTHING
---------------------
Simple: Sₜ = α·xₜ + (1-α)·Sₜ₋₁ [level only]
Holt: + Tₜ = β·(Sₜ - Sₜ₋₁) + (1-β)·Tₜ₋₁ [+ trend]
H-W: + Cₜ = γ·(xₜ/Sₜ) + (1-γ)·Cₜ₋ₗ [+ seasonality]
Parameters:
α → level responsiveness (high = reactive, low = smooth)
β → trend responsiveness
γ → seasonal responsiveness
All chosen via cross-validation
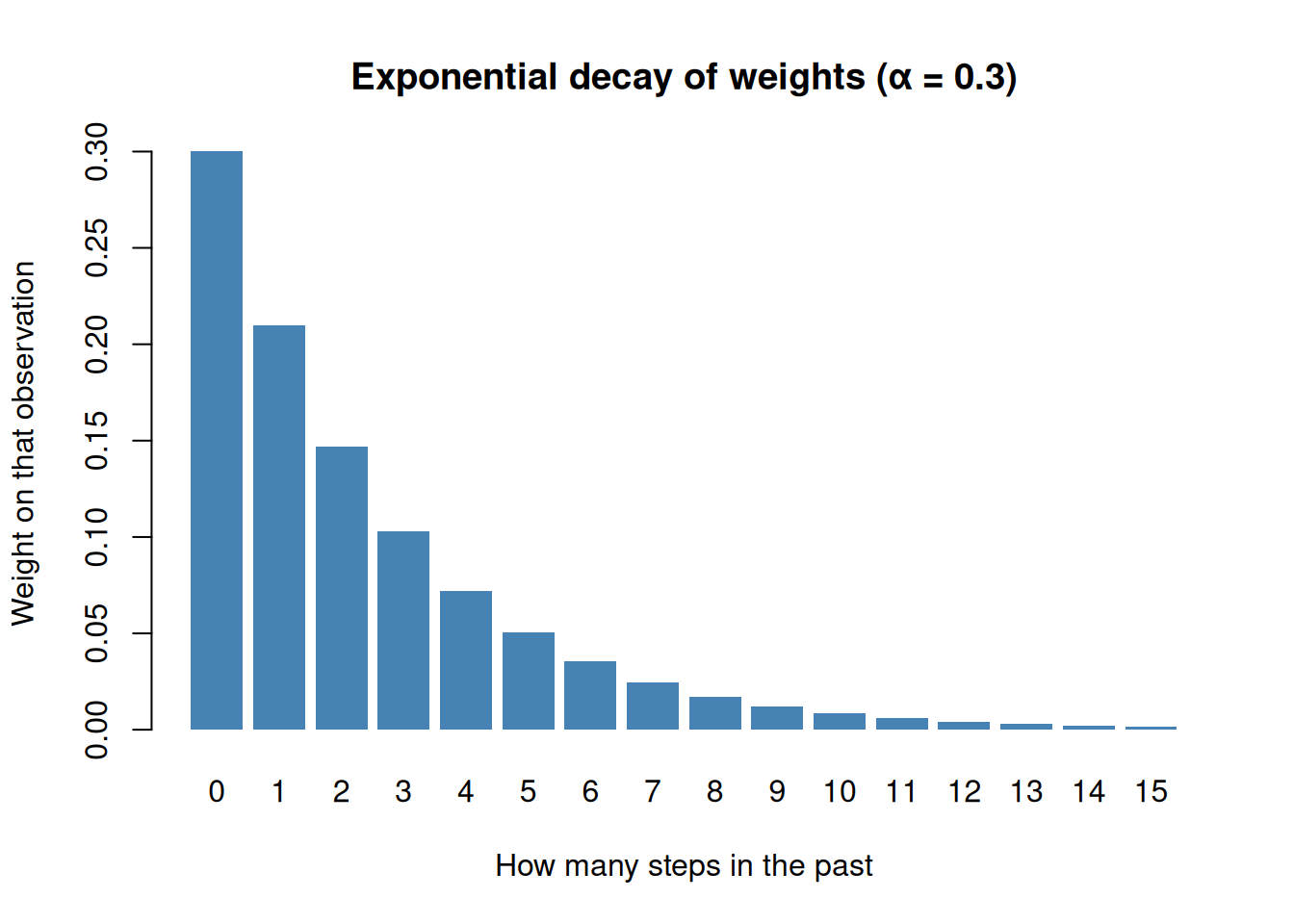
"Exponential" = past data gets exponentially decaying weights
ARIMA(p, d, q)
--------------
p = autoregressive terms (predict from past values)
d = differencing (remove trend)
q = moving average terms (correct from past errors)
ARIMA(0,1,1) = simple exponential smoothing
Use when: stable data, 40+ observations, complex patterns
GARCH(p, q)
-----------
σₜ² = ω + α·εₜ₋₁² + β·σₜ₋₁²
Forecasts VARIANCE, not value.
Use when: "volatility", "risk", "how much will values vary"
PRACTICAL DECISION:
"Forecast the value" → ES or ARIMA
"Forecast the variance/volatility" → GARCH
"Detect a change" → CUSUM
11. Check Your Understanding
NoteTest Yourself
Before moving on, try to answer these without scrolling up:
What does \(\alpha\) control in exponential smoothing? What happens when you increase it?
Why is it called “exponential” smoothing?
When do you need Holt’s method instead of simple ES?
What does the “d” in ARIMA stand for, and why is it needed?
What is the key difference between ARIMA and exponential smoothing? When would you prefer each?
GARCH forecasts _______, not _______. (Fill in the blanks.)
A manager asks you to “predict next quarter’s sales.” Which method? Now they ask “predict how volatile next quarter’s sales will be.” Which method?
What is ARIMA(0,1,1) equivalent to?
Data has 20 observations, lots of noise, and a seasonal pattern. Exponential smoothing or ARIMA? Why?