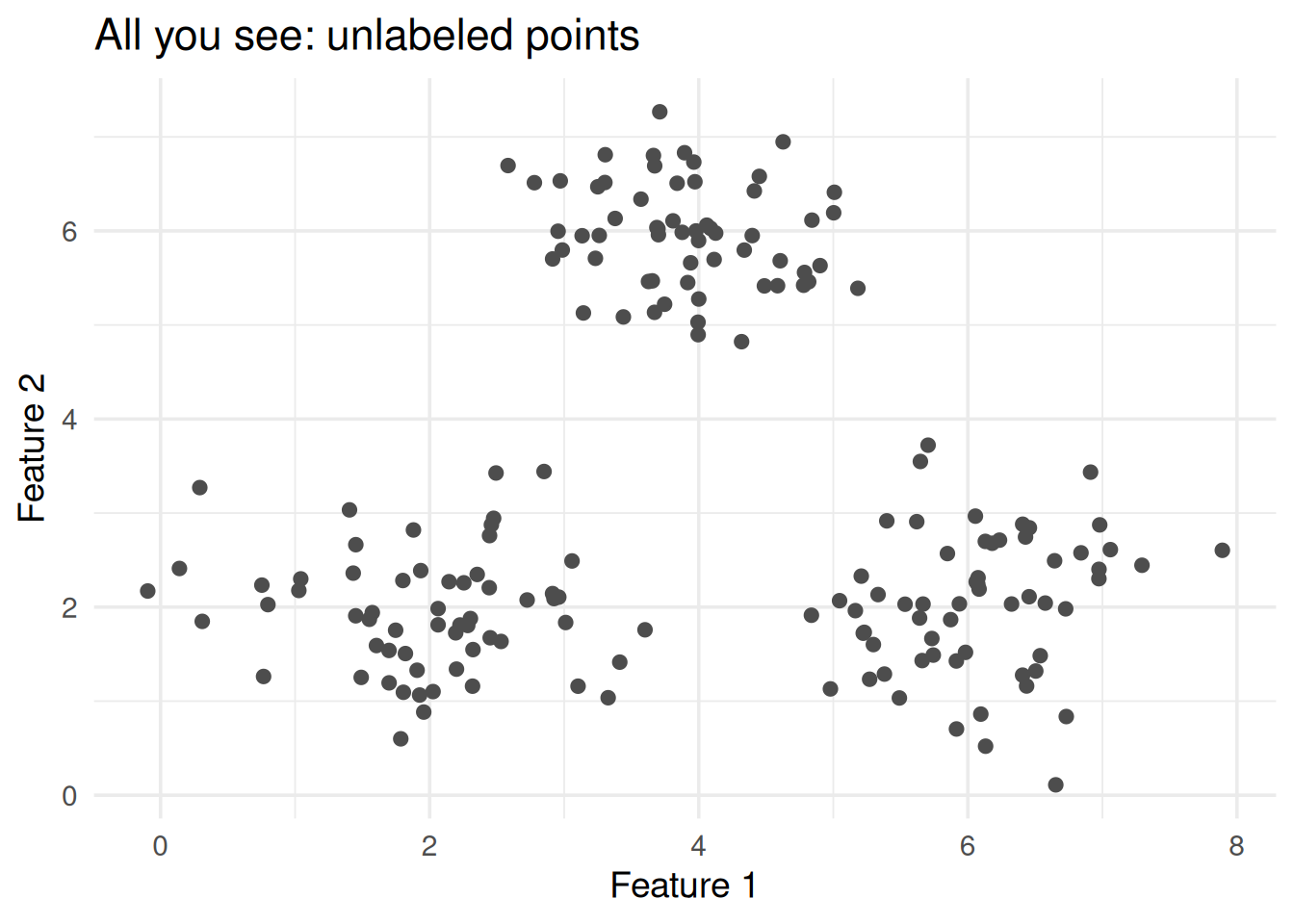
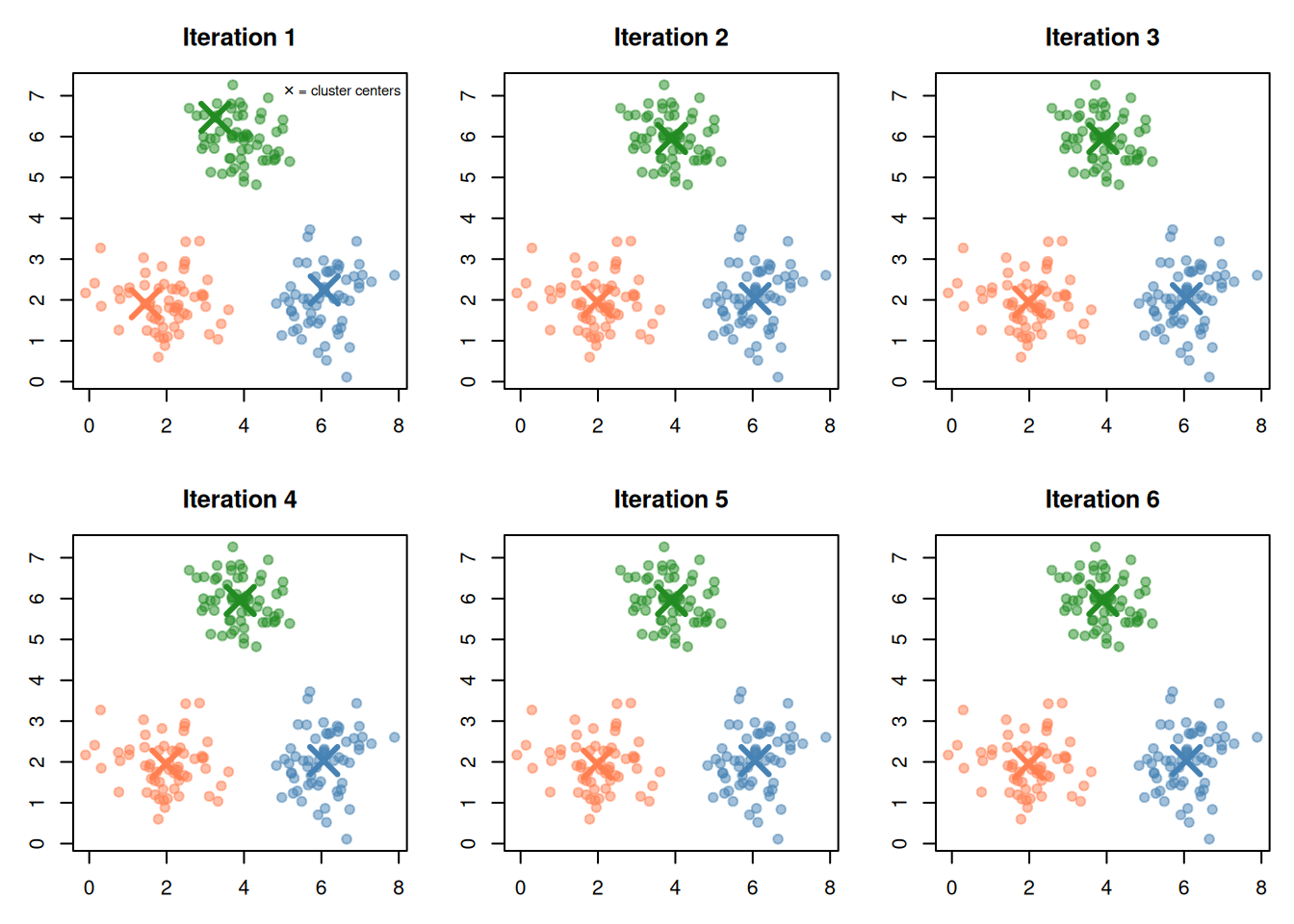
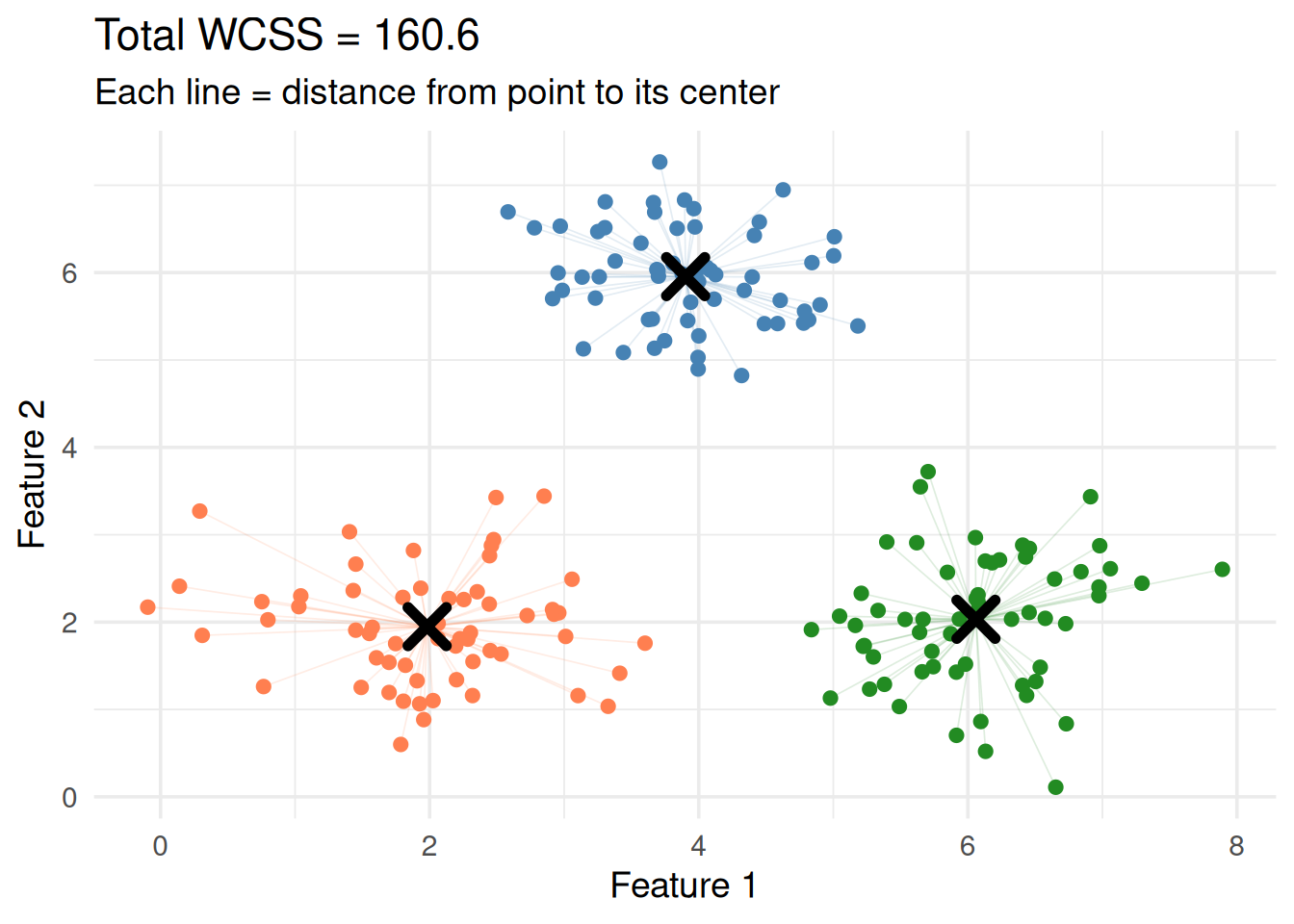
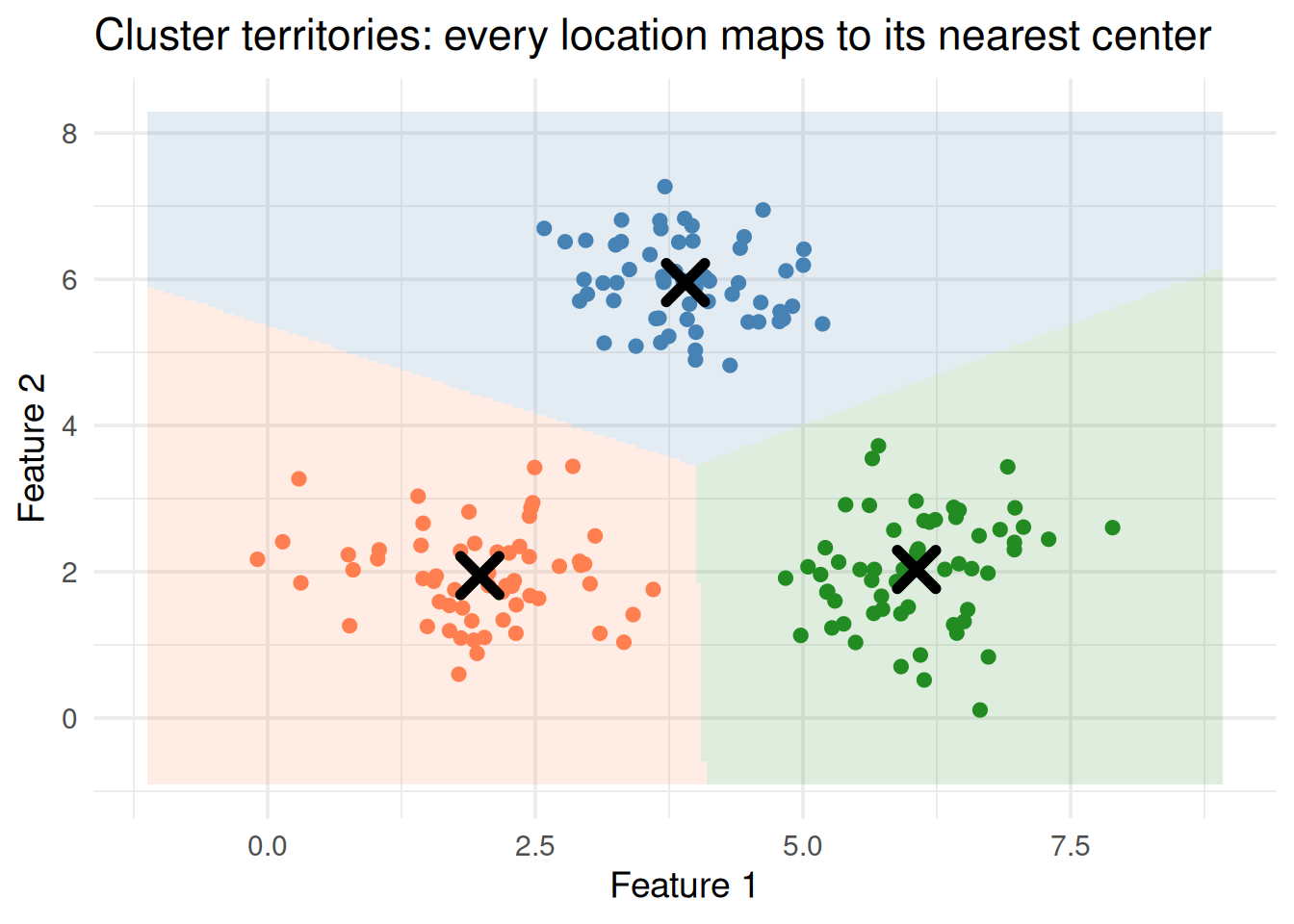
Figure 4: Each region contains all points closest to that center (Voronoi diagram)
5. Choosing k: The Elbow Method
The hardest part of k-means: how many clusters? There’s no formula. You use the elbow method:
Run k-means for \(k = 1, 2, 3, \dots\)
Record the total WCSS for each \(k\)
Plot \(k\) vs WCSS
Look for the elbow — where the curve bends and adding more clusters stops helping much
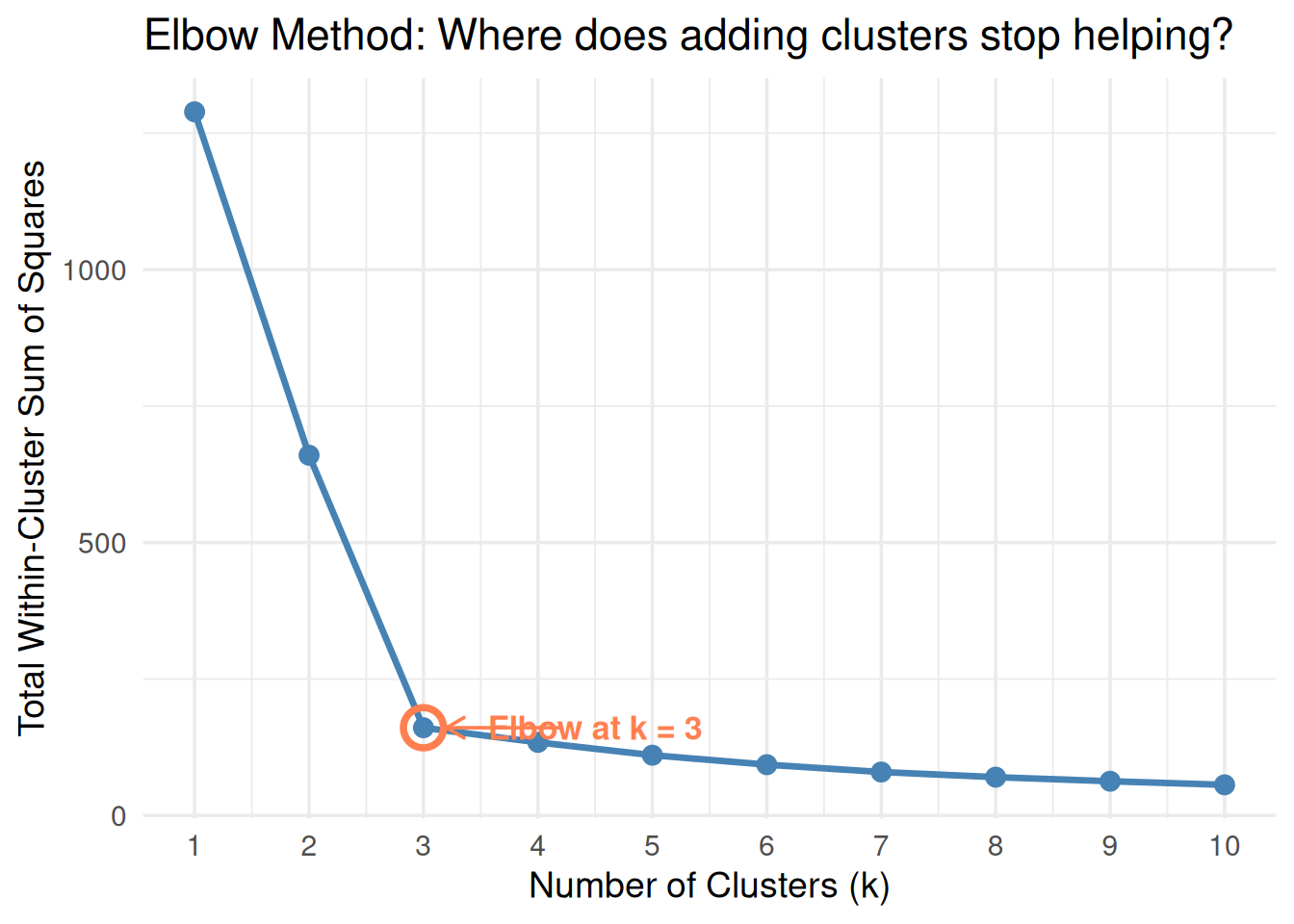
k_range <-1:10wcss <-sapply(k_range, function(k) { km_fit <-kmeans(df[, c("x1", "x2")], centers = k, nstart =20) km_fit$tot.withinss})elbow_df <-data.frame(k = k_range, wcss = wcss)ggplot(elbow_df, aes(k, wcss)) +geom_line(linewidth =1.2, color ="steelblue") +geom_point(size =3, color ="steelblue") +geom_point(data = elbow_df[3, ], aes(k, wcss),size =6, shape =1, color ="coral", stroke =2) +annotate("text", x =4.5, y = wcss[3],label ="Elbow at k = 3", color ="coral", size =4.5, fontface ="bold") +annotate("segment", x =4.2, xend =3.2, y = wcss[3], yend = wcss[3],arrow =arrow(length =unit(0.3, "cm")), color ="coral") +scale_x_continuous(breaks = k_range) +theme_minimal(base_size =14) +labs(x ="Number of Clusters (k)", y ="Total Within-Cluster Sum of Squares",title ="Elbow Method: Where does adding clusters stop helping?")
Figure 5: The elbow method: WCSS drops sharply, then flattens — the bend is your k
Why \(k = 3\) here? Going from 2 to 3 clusters gives a big drop in WCSS. Going from 3 to 4 gives almost nothing. The “elbow” bends at 3.
Important: The elbow is a judgment call, not an exact calculation. Sometimes the elbow is obvious; sometimes it’s ambiguous. In this guide, the setup will make it clear.
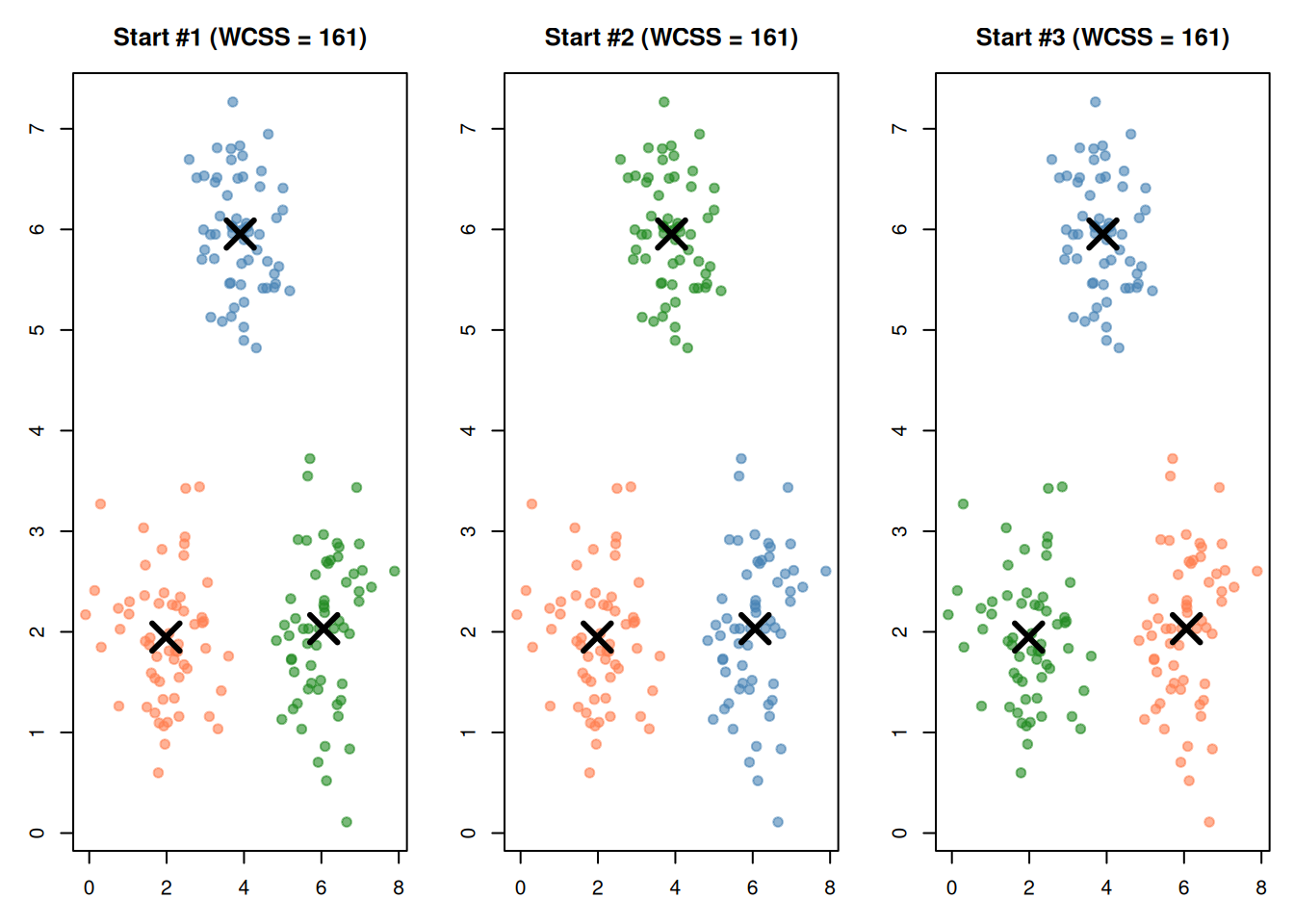
6. The Random Initialization Problem
k-means starts with random centers. Different starting positions can lead to different results — sometimes bad ones.
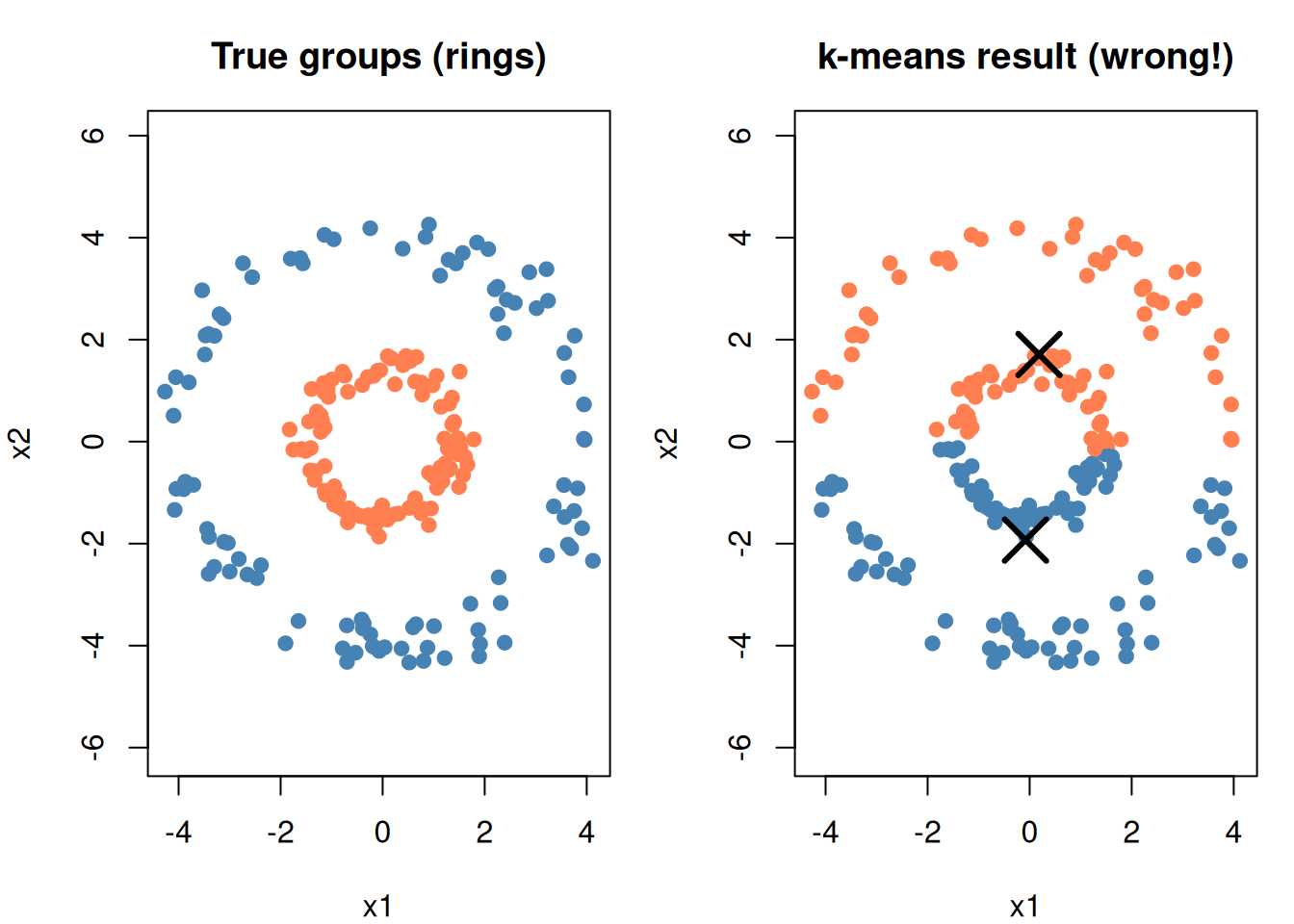
k-means draws boundaries equidistant from centers — producing circular (spherical) regions. Data with elongated, curved, or irregular shapes won’t cluster well.
set.seed(42)# Concentric rings (k-means will fail)n <-200angle <-runif(n, 0, 2* pi)r_inner <-rnorm(n /2, 1.5, 0.2)r_outer <-rnorm(n /2, 4, 0.3)rings <-data.frame(x1 =c(r_inner *cos(angle[1:(n/2)]), r_outer *cos(angle[(n/2+1):n])),x2 =c(r_inner *sin(angle[1:(n/2)]), r_outer *sin(angle[(n/2+1):n])),true =factor(rep(c("Inner", "Outer"), each = n /2)))km_rings <-kmeans(rings[, 1:2], 2, nstart =20)par(mfrow =c(1, 2), mar =c(4, 4, 3, 1))plot(rings$x1, rings$x2,col =c("coral", "steelblue")[as.numeric(rings$true)],pch =19, main ="True groups (rings)",xlab ="x1", ylab ="x2", asp =1)plot(rings$x1, rings$x2,col =c("coral", "steelblue")[km_rings$cluster],pch =19, main ="k-means result (wrong!)",xlab ="x1", ylab ="x2", asp =1)points(km_rings$centers[, 1], km_rings$centers[, 2],pch =4, cex =3, lwd =3)par(mfrow =c(1, 1))
Figure 10: k-means struggles with non-spherical shapes
Other limitations
You must choose k in advance — the algorithm can’t decide for you
Sensitive to outliers — a single extreme point can pull a center away
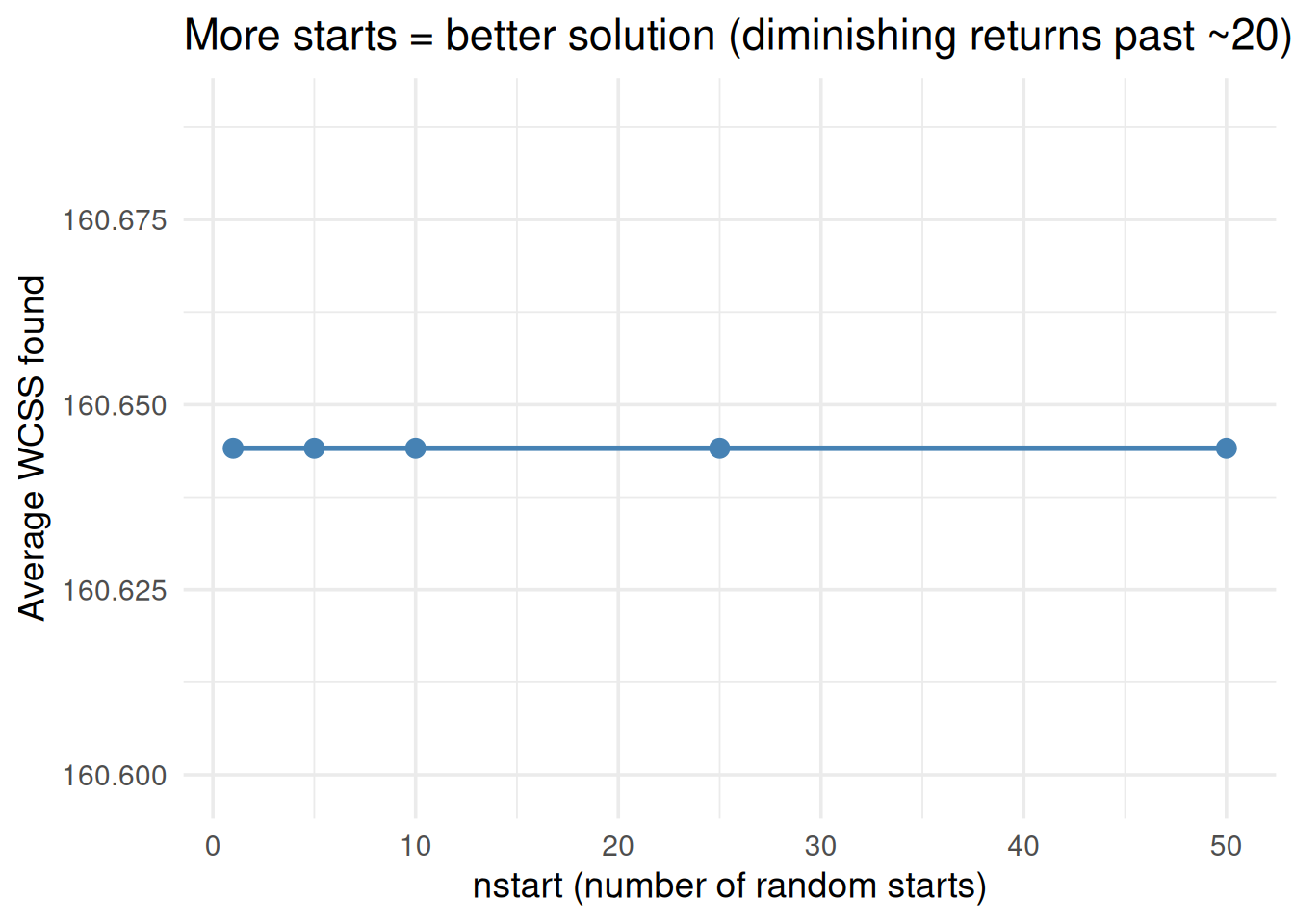
Random starts — can get stuck in bad solutions (fix: use nstart)
Only finds convex clusters — can’t wrap around shapes
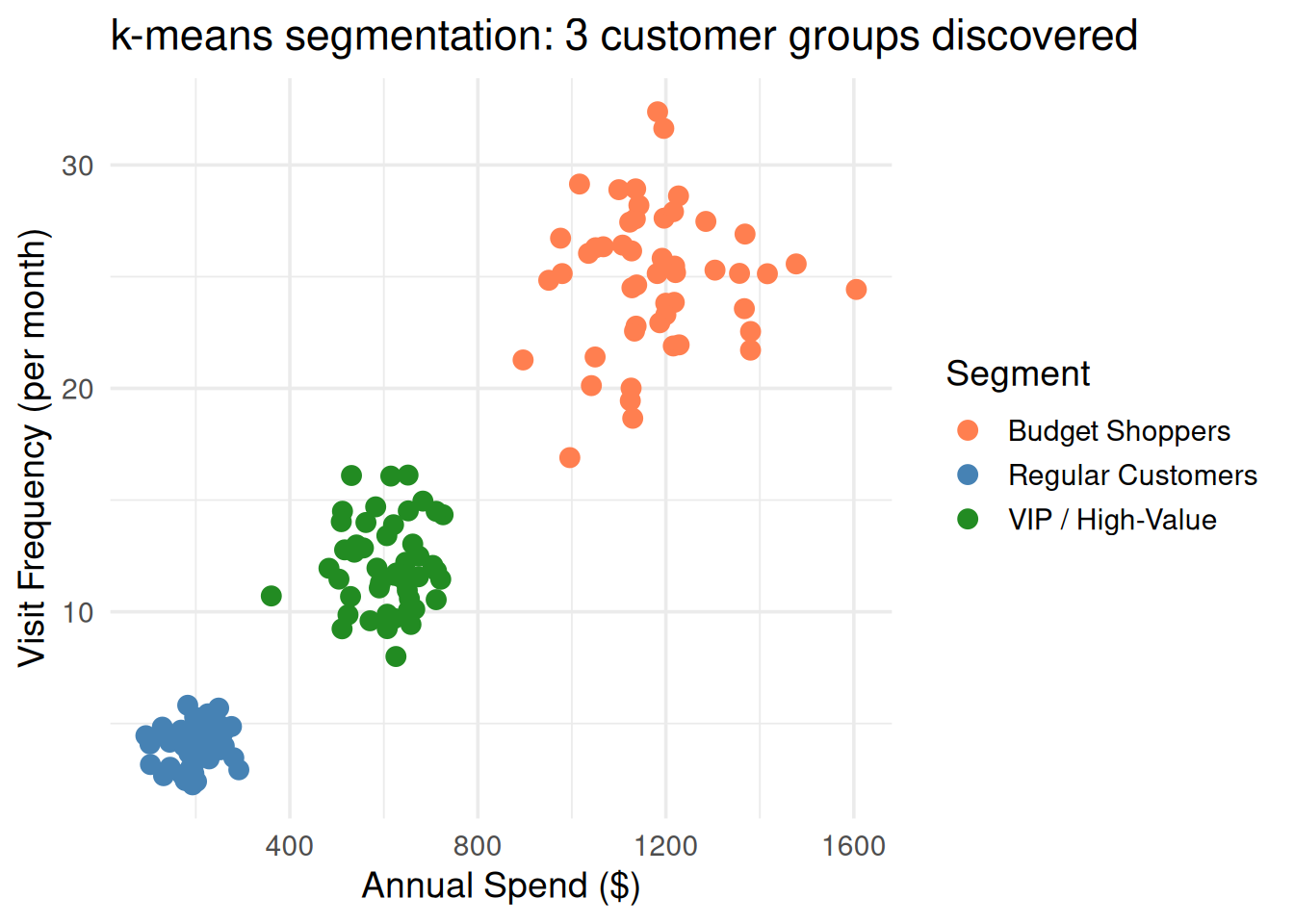
10. Practical Use: Customer Segmentation
This is the classic practice scenario. You have customer data, no labels, and the business wants to know: what types of customers do we have?
Figure 11: Customer segmentation: k-means discovers 3 natural groups from spending data
The workflow:
Collect customer features (spend, visits, demographics, etc.)
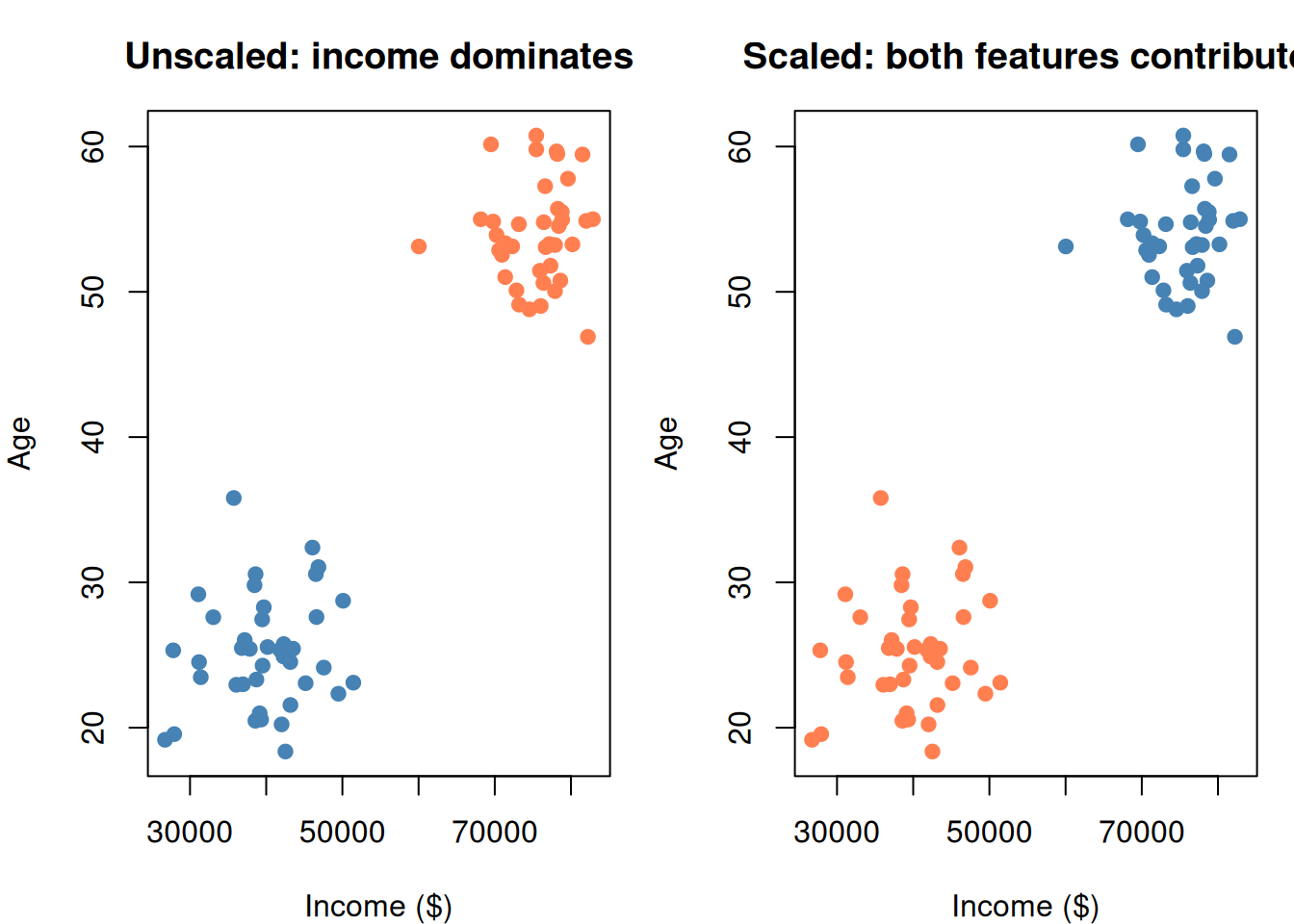
Scale the features
Use elbow method to choose \(k\)
Run k-means with nstart = 20
Interpret the clusters → give them business-meaningful names
Build different strategies per segment
11. Cheat Sheet: The Whole Story on One Page
THE k-MEANS RECIPE
===================
1. ALGORITHM (repeat until convergence):
- Assign each point to nearest center
- Move each center to mean of its points
2. THE FORMULA:
min Σⱼ Σᵢ∈Cⱼ ||xᵢ - μⱼ||²
-------------------------
"total distance from points
to their cluster centers"
Center of cluster j: μⱼ = (1/|Cⱼ|) × Σ xᵢ
3. KEY PARAMETER:
k → number of clusters (choose via elbow method)
4. ELBOW METHOD:
Plot k vs WCSS → pick the "bend" point
5. GOTCHAS:
- Random initialization → use nstart = 20
- ALWAYS scale features first
- Assumes spherical clusters
- You must choose k in advance
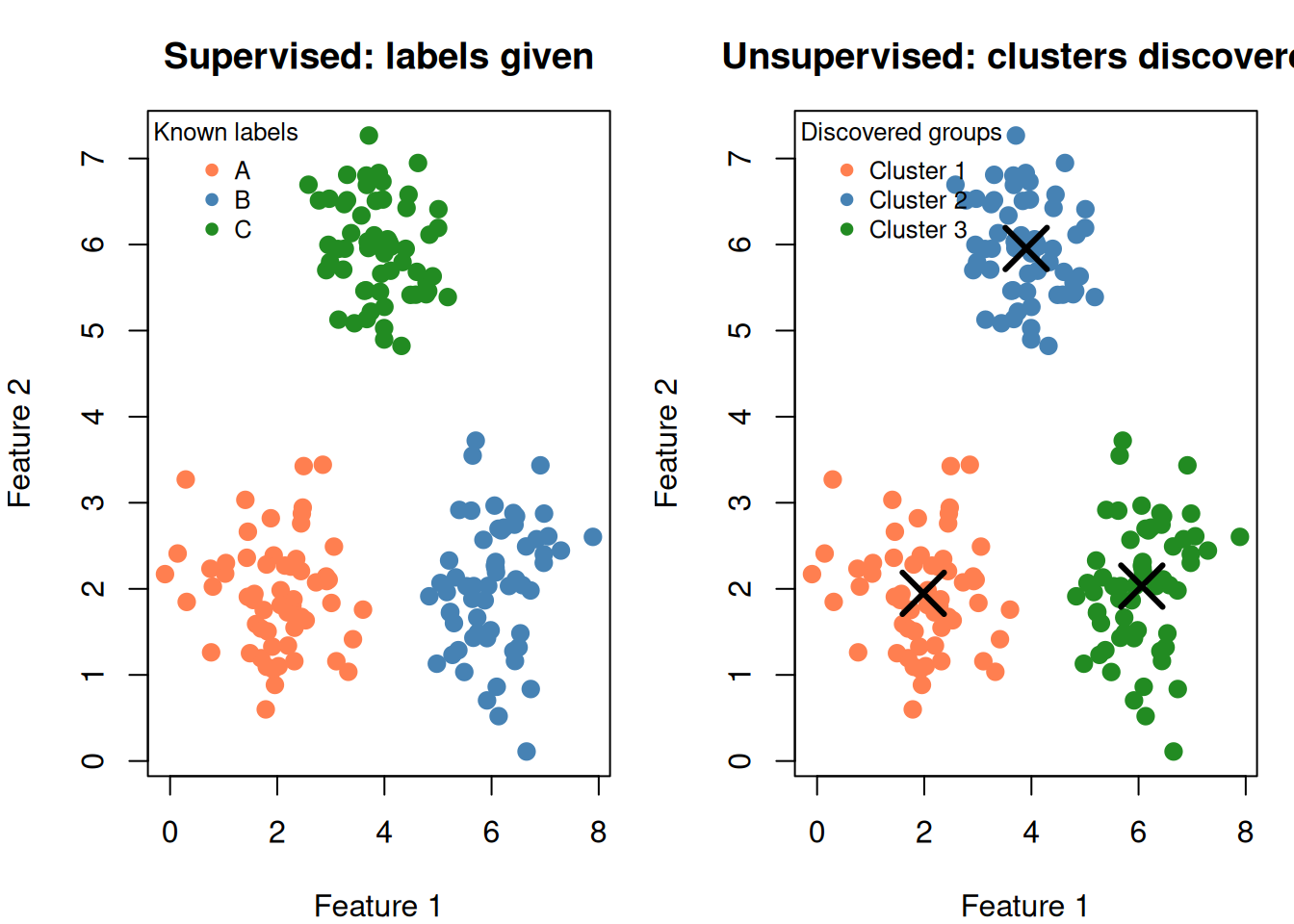
6. SUPERVISED vs UNSUPERVISED:
Labels → supervised (SVM, KNN)
No labels → unsupervised (k-means)
7. PRACTICE TIP:
"Segment customers" / "find groups" / "no labels" → k-means
"Classify" / "predict category" / "labeled data" → SVM, KNN
12. Check Your Understanding
NoteTest Yourself
Before moving on, try to answer these without scrolling up:
What makes k-means unsupervised? How is this different from KNN?
Describe the k-means algorithm in 4 steps.
What does k-means minimize? Write the formula in words.
Why is the centroid the mean of the cluster points?
How does the elbow method work? What are you plotting?
Why do you need to run k-means with multiple random starts?
Give a scenario where k-means would fail. Why does it fail?
A question says “we have customer purchase data and want to identify different customer types.” Which model? Why not SVM?