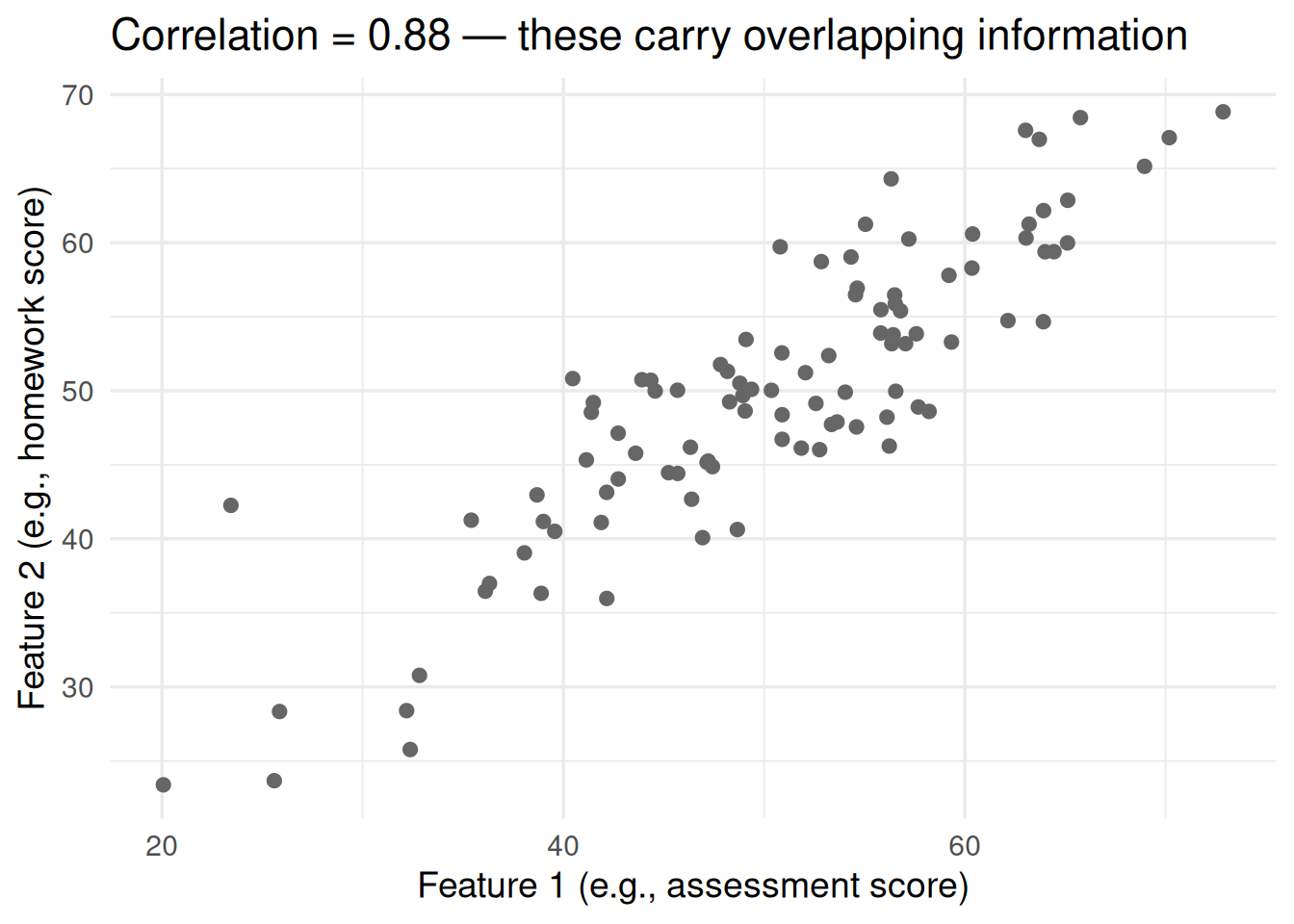
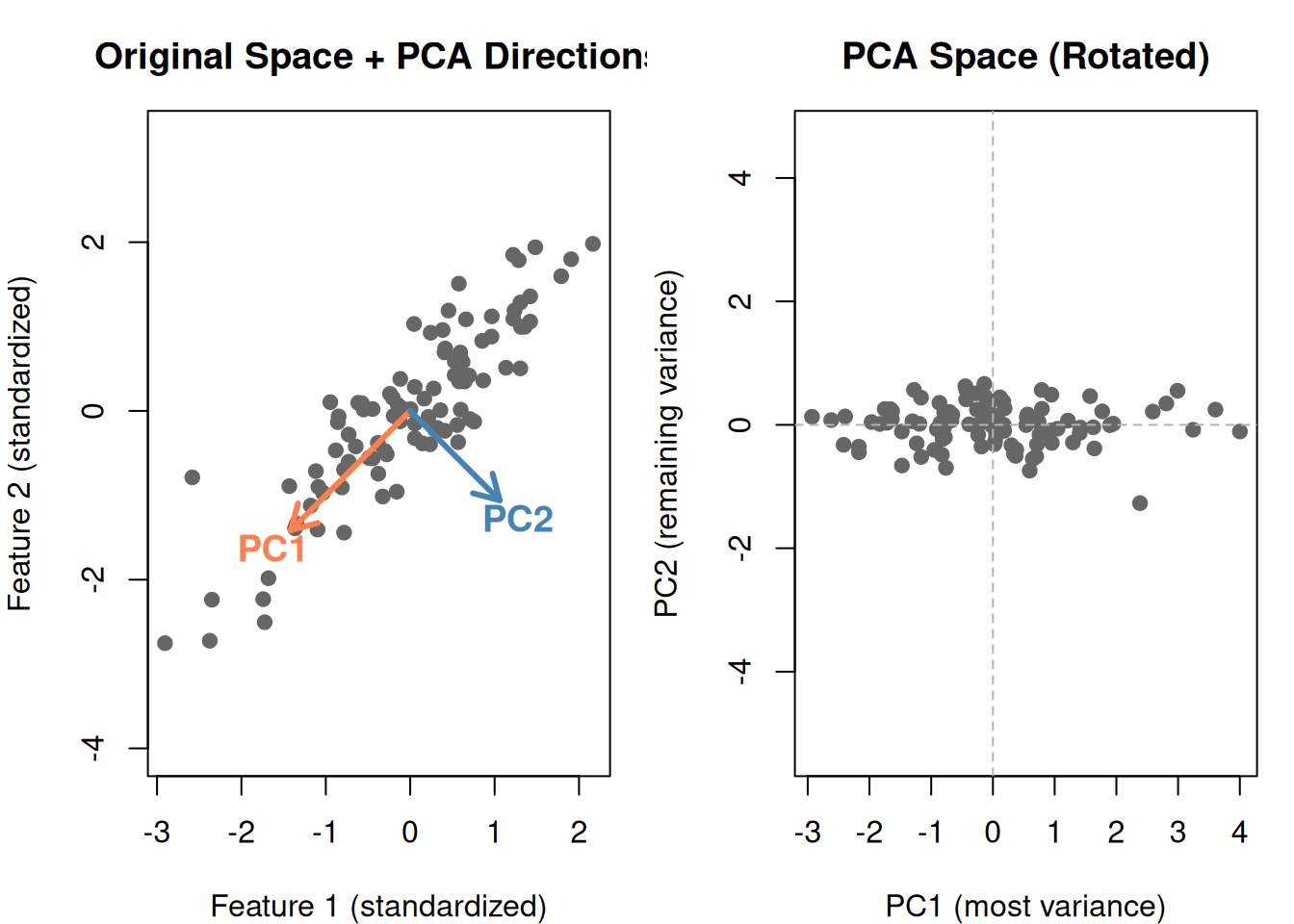
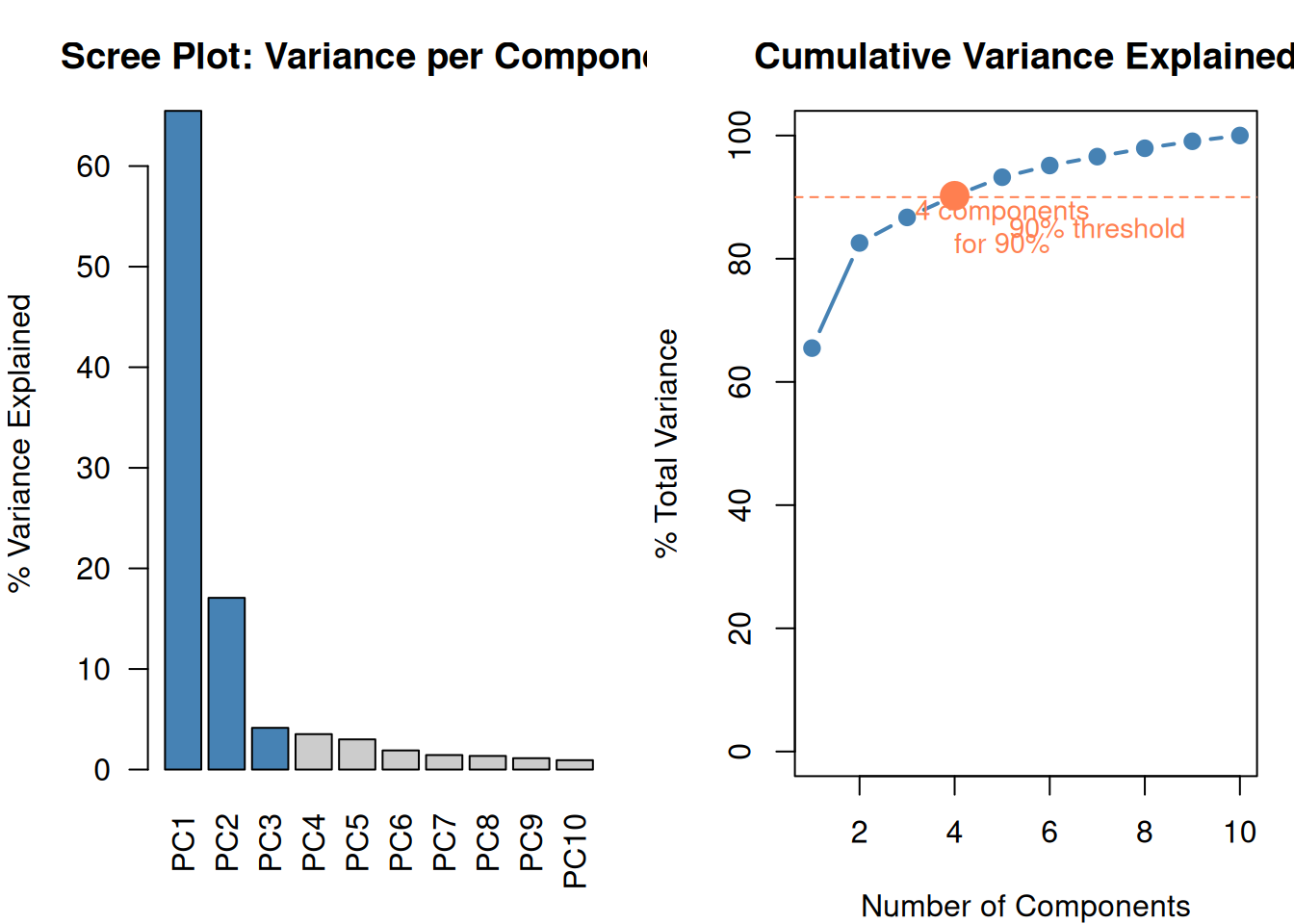
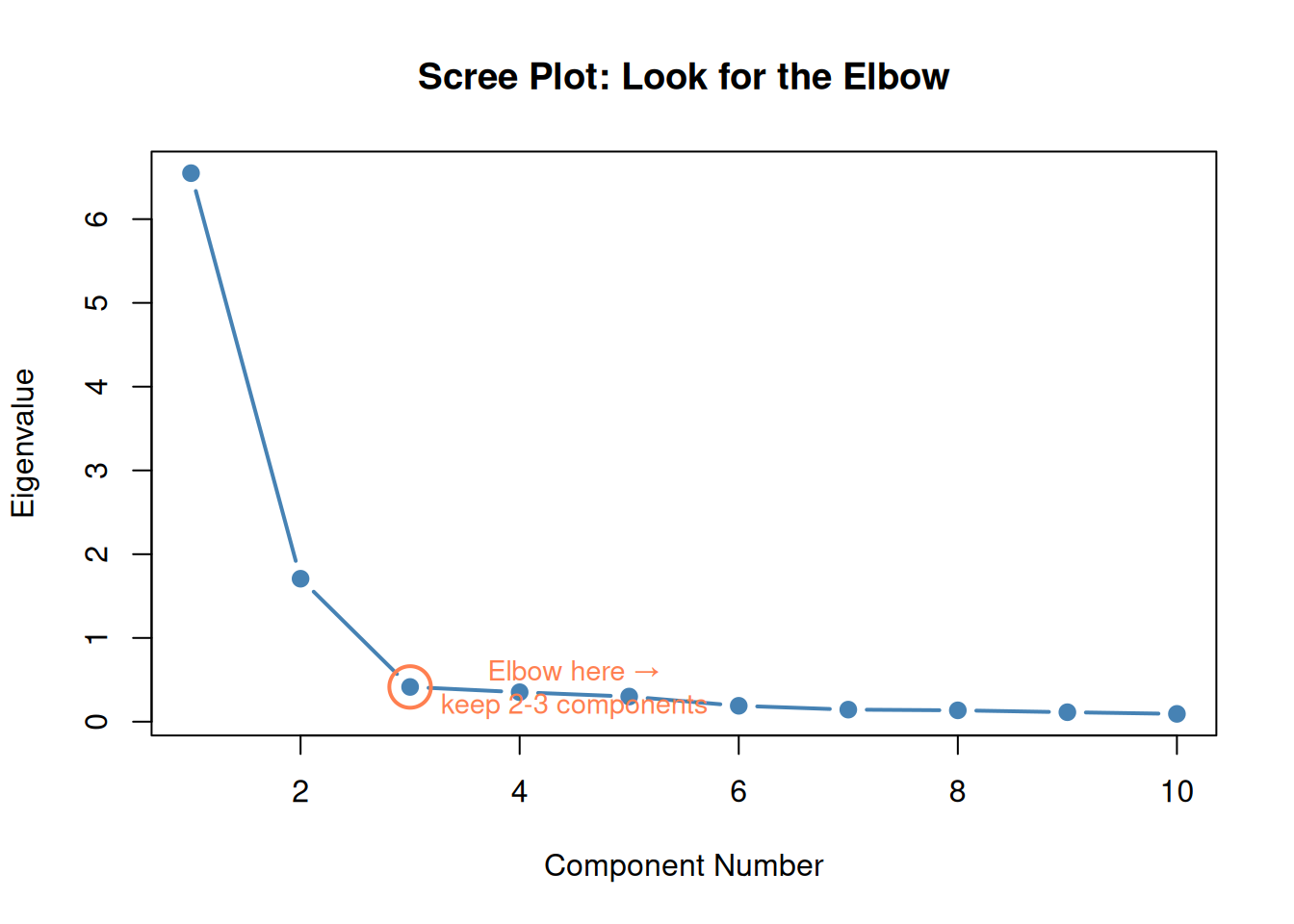
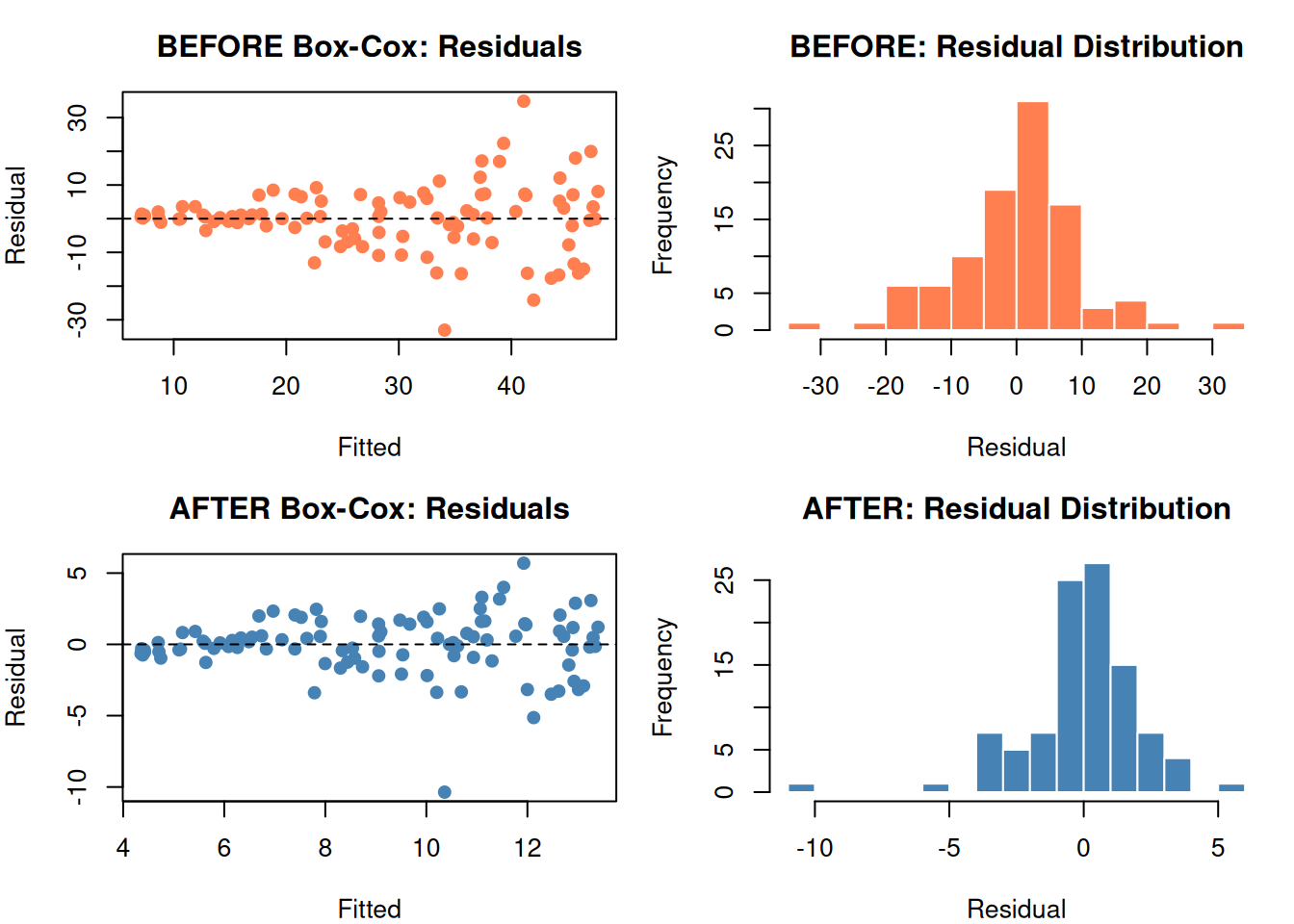
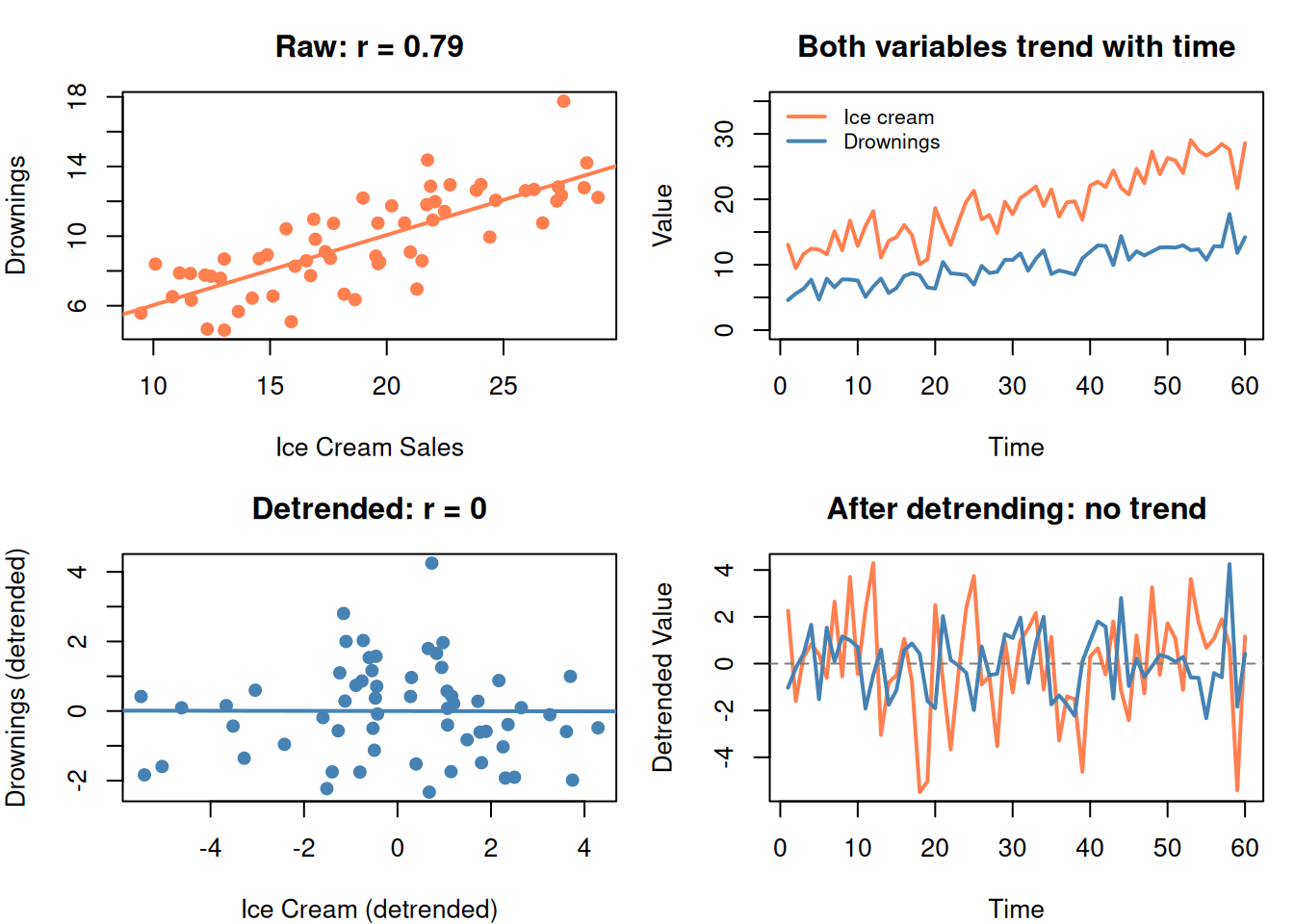
set.seed(42)
time_dt <- 1:60
# Two UNRELATED things that both trend upward
ice_cream <- 10 + 0.3 * time_dt + rnorm(60, 0, 2)
drownings <- 5 + 0.15 * time_dt + rnorm(60, 0, 1.5)
par(mfrow = c(2, 2), mar = c(4, 4, 3, 1))
# Raw correlation (spurious)
plot(ice_cream, drownings, pch = 19, col = "coral",
main = paste0("Raw: r = ", round(cor(ice_cream, drownings), 2)),
xlab = "Ice Cream Sales", ylab = "Drownings")
abline(lm(drownings ~ ice_cream), col = "coral", lwd = 2)
# Both trending
plot(time_dt, ice_cream, type = "l", col = "coral", lwd = 2,
main = "Both variables trend with time",
xlab = "Time", ylab = "Value", ylim = c(0, 35))
lines(time_dt, drownings, col = "steelblue", lwd = 2)
legend("topleft", legend = c("Ice cream", "Drownings"), bty = "n",
col = c("coral", "steelblue"), lwd = 2, cex = 0.8)
# Detrend
ice_dt <- residuals(lm(ice_cream ~ time_dt))
drown_dt <- residuals(lm(drownings ~ time_dt))
# Detrended correlation (real)
plot(ice_dt, drown_dt, pch = 19, col = "steelblue",
main = paste0("Detrended: r = ", round(cor(ice_dt, drown_dt), 2)),
xlab = "Ice Cream (detrended)", ylab = "Drownings (detrended)")
abline(lm(drown_dt ~ ice_dt), col = "steelblue", lwd = 2)
# Detrended series
plot(time_dt, ice_dt, type = "l", col = "coral", lwd = 2,
main = "After detrending: no trend",
xlab = "Time", ylab = "Detrended Value")
lines(time_dt, drown_dt, col = "steelblue", lwd = 2)
abline(h = 0, lty = 2, col = "gray50")
par(mfrow = c(1, 1))